苹果财报:全球营收 940 亿美元

苹果回应「微博放错视频」

扎克伯格:未来不用 AI 眼镜就吃亏了

大众 CEO:GTI 会一直卖到 2030 年的

机构:2029 年全球机器人市场规模超 4000 亿美元

理想回应 8 吨重卡撞不过新车

罗马仕员工回应「公司破产」

字节扣子团队公布「开源理由」

腾讯研究院圆桌实录:AI 发展下,人的想象力却变成最后的独特优势

大疆首款 360 全景相机发布

Manus 上线「广泛研究」

租电 17.98 万元起,乐道 L90 正式开售

网易云音乐起诉 SM 娱乐

「鼠标手」被纳入职业病

苹果财报:全球营收 940 亿美元
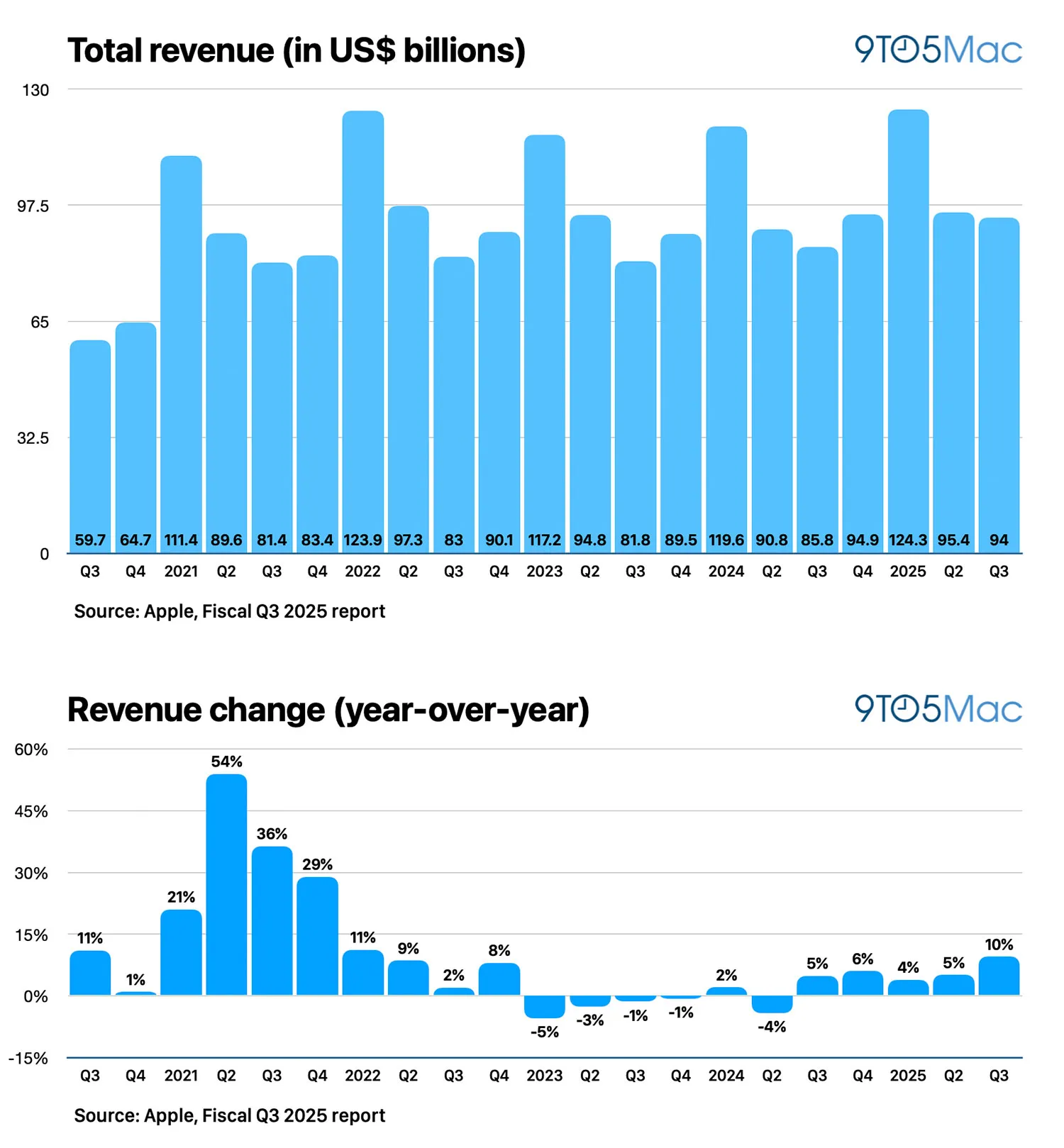
今天凌晨,苹果正式公布了 2025 财年第 3 财季最新财报(截至 6 月 29 日),具体来看:
总营业收入为 940.4 亿美元(约合人民币 6771 亿元),同比增长 10%;大中华区营业收入为 153.7 亿美元(约合人民币 1106 亿元),相比较去年同期的 147.28 亿美元,同比增长 4.35%;净利润达 234.3 亿美元。
其中,iPhone 收入达 445.8 亿美元;iPad 收入为 65.8 亿美元;Mac 收入为 80.5 亿美元;可穿戴设备、家居和配件收入为 74 亿美元;服务收入达 274.2 亿美元。
据 9to5Mac 报道,在该财季的电话会上,苹果 CEO 库克表示,中国市场的 iPhone 销量实现反弹,相比上一季度,该地区总收入增长 4.35%。他还表示,中国的 iPhone 用户数量达到历史新高,并且销量回升的主要原因是国补政策。另外,库克在接受 CNBC 采访时表示,iPhone 16 相比去年同期的 iPhone 15 更受欢迎。
同时,库克还宣布,自 2007 年推出以来,苹果已累计出货 30 亿部 iPhone,创造了新的里程碑。据悉,苹果于 2016 年 7 月宣布 iPhone 全球累计出货量达 10 亿部。
库克还在电话会上表示,Mac、iPad、Apple Watch 等产品也深受中国消费者青睐。其中 MacBook Air 是中国最畅销的笔记本电脑机型,Mac Mini 是中国最畅销的台式机机型。
在 AI 领域,库克也透露了更多相关进展。其表示,公司正在「大幅增加」AI 领域的投资,并且对能「加速技术路线图」的并购持开放态度。
库克还表示,苹果在更加个性化的 Siri(开发)方面取得不错的进展,并正如苹果所承诺,该公司预计将在明年正式发布相关功能。此外,库克高度评价 AI 的价值,称其为「我们一生当中最深远的技术之一」。
库克在接受 CNBC 采访时透露,苹果 2025 年迄今为止已收购「大约 7 家公司」,但「没有一起是金额巨大的」。

苹果回应「微博放错视频」
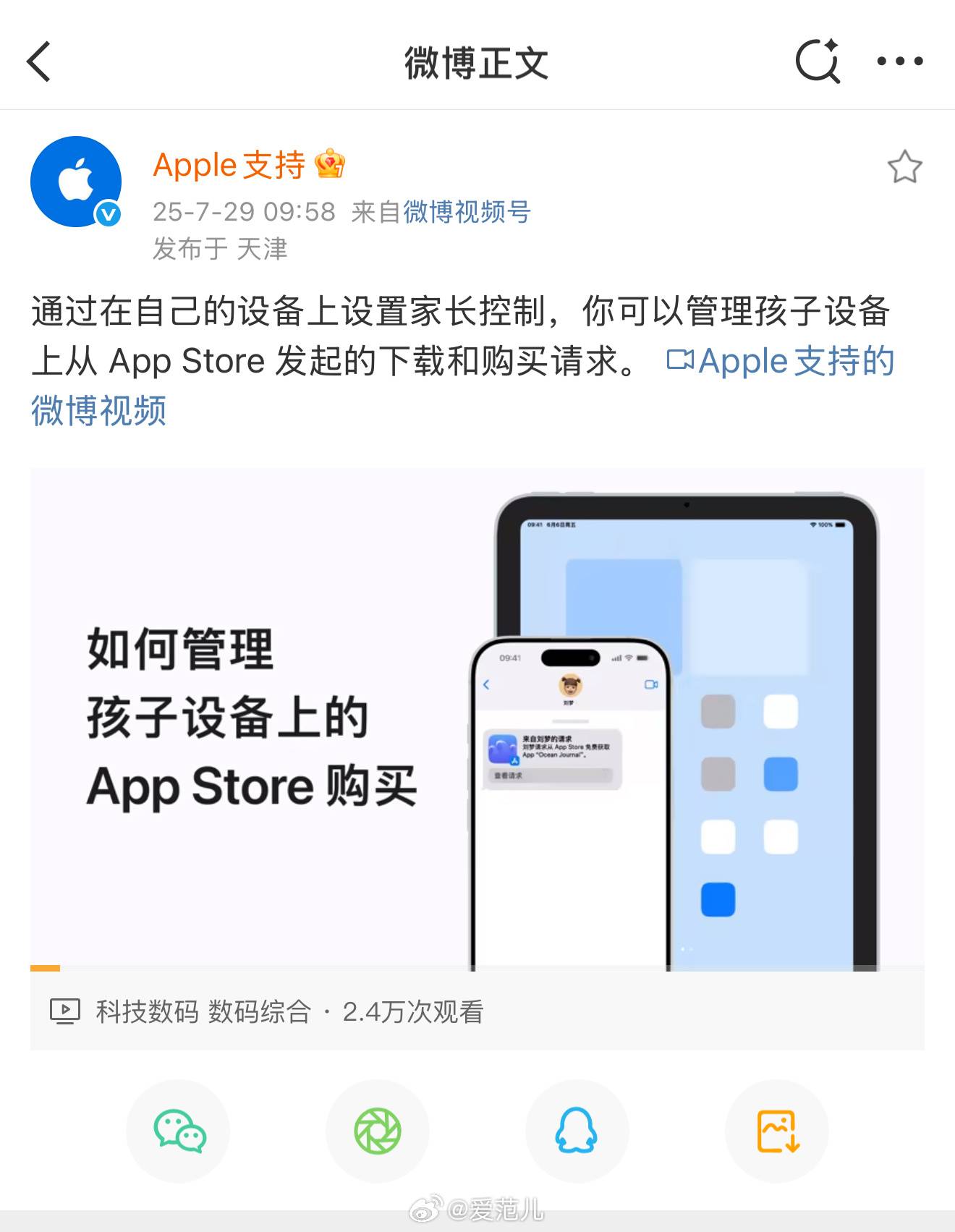
日前,有媒体报道称「苹果官方微博闹乌龙」,表示刷到苹果官方账号「Apple 支持」发表了一条关于苹果设备的家长控制功能的介绍微博,但该微博下方的视频却是三星 Z Flip 7 的宣传视频。
但我们在 7 月 29 日就已经刷到过这条微博内容,彼时并未出现任何异常情况。目前,该微博的状态依然正常,并未看到有「已编辑」的二次编辑标记。
而苹果官方昨日也就上述事件发表了声明:
Apple 支持仅发布过 Apple 相关内容。我们正与微博沟通,以调查此事的发生原因。
考虑到此前网传的截图是来自微博国际版客户端,所以我们猜测,这很可能是因为数据流、缓存,或其他原因,而导致的视频错位现象。
昨晚,新浪微博 CEO 王高飞(来去之间)发文表示,本次苹果的视频异常是微博轻享版客户端的一个 Bug——本地缓存问题。
扎克伯格:未来不用 AI 眼镜就吃亏了
据 TechCrunch 报道,Meta CEO 扎克伯格日前在公司第二季度财报会上,向投资者表示,其认为未来没有使用 AI 眼镜的人将会处于竞争劣势。
「我始终认为眼镜本质上将是 AI 的理想载体,因为它能够让 AI 全天候感知你的所见所闻,并与你交流,」扎克伯格还表示,为 AI 眼镜添加显示屏还会释放出该品类的巨大价值。
值得一提的是,Meta 此前曾发布了一款配备显示技术的 AI AR 眼镜 Orion,并且有望在未来推出类似 Orion 的可显示 AI 眼镜。
扎克伯格进一步表示,「我认为未来如果没有使用 AI 的眼镜,或是没有其他与 AI 交互的手段,相比他人,你可能会处于相当显著的认知劣势。」
近日,扎克伯格还发表了一封公开信,透露了 Meta 将目标定在了打造超级智能。
其在信中坦言,自己对超级智能帮助人类加速进步持积极乐观态度,但更重要的是,超级智能有望开启个人赋权的新纪元——人们将拥有更大的自主权,按照自己选择的方向来改变世界。
大众 CEO:GTI 会一直卖到 2030 年的
据 motor1 报道,大众汽车 CEO Thomas Schäfer 日前确认,旗下高尔夫 GTI 车型将会被保留到 2030 年。
「(高尔夫 GTI)在 2030 年绝对会继续存在,而内燃机车型仍将保持强劲的存在」,Thomas 在日前的一次采访中表示。但值得一提的是,Thomas 也透露,「(GTI)可能会加入一些电气化元素」。
值得一提的是,目前大众高尔夫存在插电混动版的 GTE 车型。报道指出,若 Thomas 透露的内容属实,那么未来 GTI 和 GTE 可能将会合并为一款车型。
据悉,大众此前已确认将在本年代末(2030 年前)推出第九代高尔夫,届时该车型也将全面走向电动化。而 Thomas 所指的 2030 年仍存在的燃油车型,或为目前的第八代高尔夫(该车型或持续生产至 2035 年)。
机构:2029 年全球机器人市场规模超 4000 亿美元
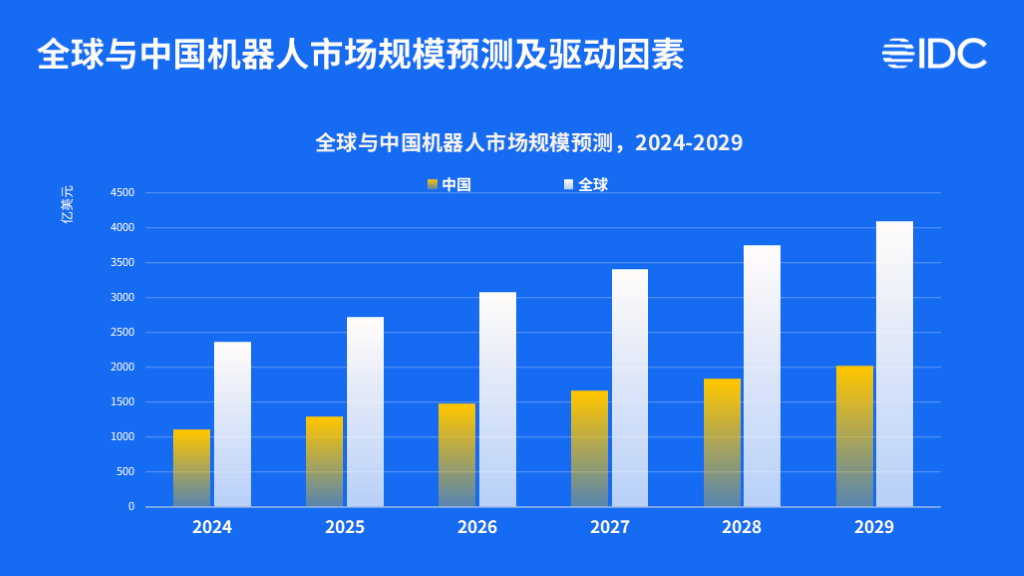
昨日,数据机构 IDC 发文预测称,到 2029 年全球机器人市场规模将超过 4000 亿美元。
IDC 指出,中国市场占据近半份额,并以近 15% 的复合增长率位居全球前列,成为推动全球机器人产业增长的核心引擎。具体来看:
- 商用服务机器人:2024 年,全球商用服务机器人出货量突破 10 万台,而中国厂商以 84.7% 的出货份额引领全球;
- 四足机器人:2024 年,全球四足机器人市场规模超过 1.8 亿美元,出货量约 2 万台。IDC 表示,从全球格局来看,中国厂商宇树科技、云深处依托完善的供应链体系与高度集成的产品设计,在性能表现、出货规模及开放性等方面实现突破,正逐步重塑全球市场领导格局。
- 人形机器人:在政策引导下,中国人形机器人行业正通过「技术突破—应用验证」的双向循环模式加速发展,吸引多元化厂商积极参与,协同构建产业生态,推动行业持续进步。另外,百度、华为、字节、智元机器人等企业正积极推进具身智能大模型的创新升级与应用落地。
值得一提的是,IDC 还预测 2025 年中国人形机器人商用销售出货量预计约 5 千台,2030 年将增至近 6 万台,年复合增长率超 95%。
理想回应 8 吨重卡撞不过新车

日前,理想 i8 与大货车碰撞测试冲上热搜,引发广泛关注。
从理想官方公布的视频来看,理想 i8 共经历两次卡车撞击。而在撞击后,理想 i8 的 A 柱、B 柱、C 柱、门梁均无变形,9 个气囊全部打开,电池包无漏液、无起火,车门自动解锁、门把手自动弹开。
值得一提的是,与理想 i8 撞击的卡车则出现了整个车头断裂,甚至四轮悬空的情况。
对于上述情况,理想汽车通过封面新闻回应,明确此次测试的真实性与科学性。其表示,i8 和卡车撞击的超级实验,是基于用户真实交通会车场景的模拟,全权委托专业的第三方检测机构测试认证。试验场地、测试设备以及市场端随机购买的测试卡车均由检测机构提供,理想汽车没有任何指定。
而视频当事卡车所属品牌方「乘龙卡车」(该品牌隶属东风柳州汽车有限公司),昨日也发布了声明回应了上述事件。
乘龙卡车方面指出,某汽车品牌日前发布与乘龙卡车正面碰撞视频的行为,已构成严重侵权,并超过正常商业竞争范畴,严重误导和损害公众知情权,对乘龙卡车品牌及商业名誉带来了巨大负面影响。
乘龙卡车强调,据其了解,某汽车品牌未公开测试车辆状况(双方车辆是否改装、减配、卡扣是否固定、车辆是否过检等)、场景环境(测试场地状况、车速、驾驶状态等),通过自定义碰撞条件,特定设计非常规测试场景,发布与公众认知的正常碰撞结果偏差较大的碰撞视频。
乘龙卡车表示,其对此事高度关注,将持续关注此事件,本着专业、严谨、负责的态度成立专项组进行进一步研究,并对此事造成的影响,保留追究法律责任的权利。
另外,针对此事,九派新闻以投资者身份致电对撞试验的测试方中国汽研,其证券部工作人员回应称,测试的全过程肯定符合所有的规定和标准,不会因为(哪一方)是客户,去刻意调节车辆参数。关于卡车的来源,其表示,测试卡车是一辆全新车,具体来源还需要与业务部门确认。
该工作人员还表示:「这次测试不属于公告准入测试,我们理解应该不是强制性必须做的一个(项目)业务,(测试结果)一般用于车辆的开发验证。」
昨日,理想汽车产品线负责人「老汤哥 Tango」也发文回应称,「相信权威机构的专业,要不来复测一把?」,随后理想汽车另一名产品线负责人张骁转发并表示「可以啊,直播都行」。
罗马仕员工回应「公司破产」
日前,市场流传罗马仕已进入破产程序。据蓝鲸新闻向罗马仕员工求证,该名员工表示:
国庆节前应该会有结果——由于证书暂停不得超过 3 个月,若 9 月底仍未恢复,所有库存产品都将销毁。
该人士还表示,「如果届时将无法恢复生产和售卖产品,最终要么注销,要么走向破产。」
据媒体「知危」7 月报道,目前已进行大规模停工停产的罗马仕仍有大量需要处理的问题、货物。
据报道援引罗马仕产品部员工消息,公司目前还有不少于 5000 万成本价货值的成品,都印有 LOGO 的,也不知道之后要怎么处理。员工透露,去年罗马仕营业额大概是 17-18 亿左右,其中充电宝业务占了大概 80%。
员工还表示,公司可以选择仅关闭充电宝业务,但罗马仕却选择解散所有业务。
字节扣子团队公布「开源理由」
昨日,字节旗下扣子团队发文,制作一期官方 AMA。
据悉,扣子自 2025 年 7 月 26 日在 GitHub 开源后,获得了开发者的广泛关注。当前,Coze Studio 已有 13k+ stars,Coze Loop 已有 4k stars。
「为什么决定开源扣子」,扣子运营负责人则表示,「开源的策略并不是简单敲定的,我们在内部经过了很多轮的讨论,最终才决定开源出来。」该负责人总结下来主要有三个原因:
- 顺应技术浪潮,加速生态建设:扣子团队指出,Agent 赛道正处于一个爆发式增长的时刻。其认为,未来不会是一家公司定义所有 Agent,而是由成千上万的开发者共同来定义。其希望通过开源,将扣子打造成 Agent 开发领域的「基础设施」和事实标准。
- 构建信任,拥抱透明:扣子团队表示,尤其对于 Agent 这种需要连接企业内部数据和服务的应用,信任至关重要。开源意味着将扣子的核心代码、架构和逻辑向社区公开,这是建立信任最彻底的方式。
- 驱动产品迭代,吸收全球智慧:开源能够让扣子团队直接获得来自全球一线开发者的反馈、代码贡献和创新思想。社区的需求会成为扣子迭代最直接、最宝贵的驱动力,帮助团队把产品打磨得更好,避免闭门造车。
腾讯研究院圆桌实录:AI 发展下,人的想象力却变成最后的独特优势
日前,腾讯研究院发布最新一期《仲夏六日谈》,主题为《AI 时代如何把想象力变成一种竞争优势?》。本次对话嘉宾拥有多位 AI 创企的创始人,大家分别讨论了 AI 时代下,想象力与竞争的相互转化。
主持人、腾讯研究院资深专家袁晓辉指出,在 AI 越来越具备行动力的时代,人的想象力反而可能成为最后的独特优势。围绕对未来 3 到 5 年的展望:
- 捏 Ta CEO 胡修涵预测会有个人创作者用智能体 IP 打造「一人公司」;
- 井英科技创始人朱江强调 AI 让人人都能表达内心的故事并与内容更深互动;
- 特赞科技 CEO 范凌则认为智能体将从辅助工具进化为可独立交付结果的「数字员工」,而工具公司也将向结果导向型智能体平台转型;
- 可触未来联合创始人游威则聚焦在用户习惯与 AI 产品形态的协同演进上,指出真正的机会不在模型能力本身,而在如何将其融入具体使用场景并形成用户协作新习惯。
对于「AI 是否会取代人类的主体性」这一更深层的议题,嘉宾们持有清醒的判断和复杂的情感:
- 朱江认为 AI 娱乐的终极形态可能是一种更具沉浸感的内容体验,而创作和消费在未来将趋于合一。
- 胡修涵坦言,其担忧技术过于强大会削弱文化领域的平等性,尤其是当 AI 不仅承担创作也承担评判角色时,人的创作欲望和评论权也许会被稀释。
- 范凌从历史中找到信心:就像照相机的诞生没有终结艺术,反而开启了抽象、装置、摄影等新艺术形式,AI 也未必是人类想象力的终点,而是另一个起点。

大疆首款 360 全景相机发布

昨晚,大疆正式发布了旗下首款全景相机 OSMO 360。
 详细看新品:这台全景相机,重现《F1》飞车镜头|大疆 OSMO 360 上手
详细看新品:这台全景相机,重现《F1》飞车镜头|大疆 OSMO 360 上手
新机最大亮点在于其采用了专门定制的相机传感器。与传统手机/相机的 4:3 矩形 CMOS 不同,OSMO 360 搭载了定制的 1/1.1 英寸方形 CMOS,最大化匹配全景镜头的圆形成像区域,并且降低了耗电和发热,体积重量也得到进一步优化。
画质方面,OSMO 360 实现了 8K50fps,同时支持 6K60fps 和 4K100fps 等多种规格;并且还支持 10Bit 和 D-Log M。照片方面,新机支持拍摄高达 1.2 亿像素/16K 超高清全景照片。
续航方面,OSMO 360 采用了与 Action 运动相机系列通用的1950mAh电池设计,一块电池在 8K30fps模式下能连续录制 114 分钟。另外,机身还内置 105GB 存储。
配件生态同样丰富:除了兼容 Action 系列的磁吸配件,还能通过触点连接手柄进行供电和控制。机身自带 1/4 螺口,第三方配件的选择也非常广泛。这次大疆还专门推出了适合骑行和车载的新配件。
价格方面,OSMO 360 起售价为 2999 元。
消息称奔驰新车将采用吉利插混技术
据 36 氪汽车消息,奔驰拟面向中国市场,推出一款超长续航的插电式混动新车,以参与愈发白热化的大电池插混产品竞争。而如今,奔驰初步计划与吉利汽车合作开发这款新车的插电混动系统方案。
知情人士透露,奔驰有意采用吉利旗下豪华品牌莲花跑车(此前为路特斯)的插电混动技术方案。据悉,双方正在密切洽谈,关键方向性的决策已经做出,目前还在就开发主体与细节进行协商。
报道指出,今年以来,吉利和奔驰已经开展了一系列合作。据此前报道,奔驰已经决定采购吉利系业务亿咖通和星际魅族的联合座舱方案。
据了解,莲花跑车的混动技术方案于 2024 年 11 月发布,名为「路遥」。该方案以电机驱动为主,涡轮增压发动机既可以用于发电,在高速工况也参与直驱。新方案下,整车综合续航将超 1100 公里。
另外,在 900V 技术的支持下,除了插入式快充,「路遥」还支持行驶中自主快充,解决了亏电场景性能下降的问题。
另据此前消息,奔驰这一混动新车项目已启动预研工作,新产品的定义之一便为油电同驱、超长续航,目标超过上千公里续航。而「路遥」混动技术方案的确符合奔驰新车的部分预期。
Manus 上线「广泛研究」
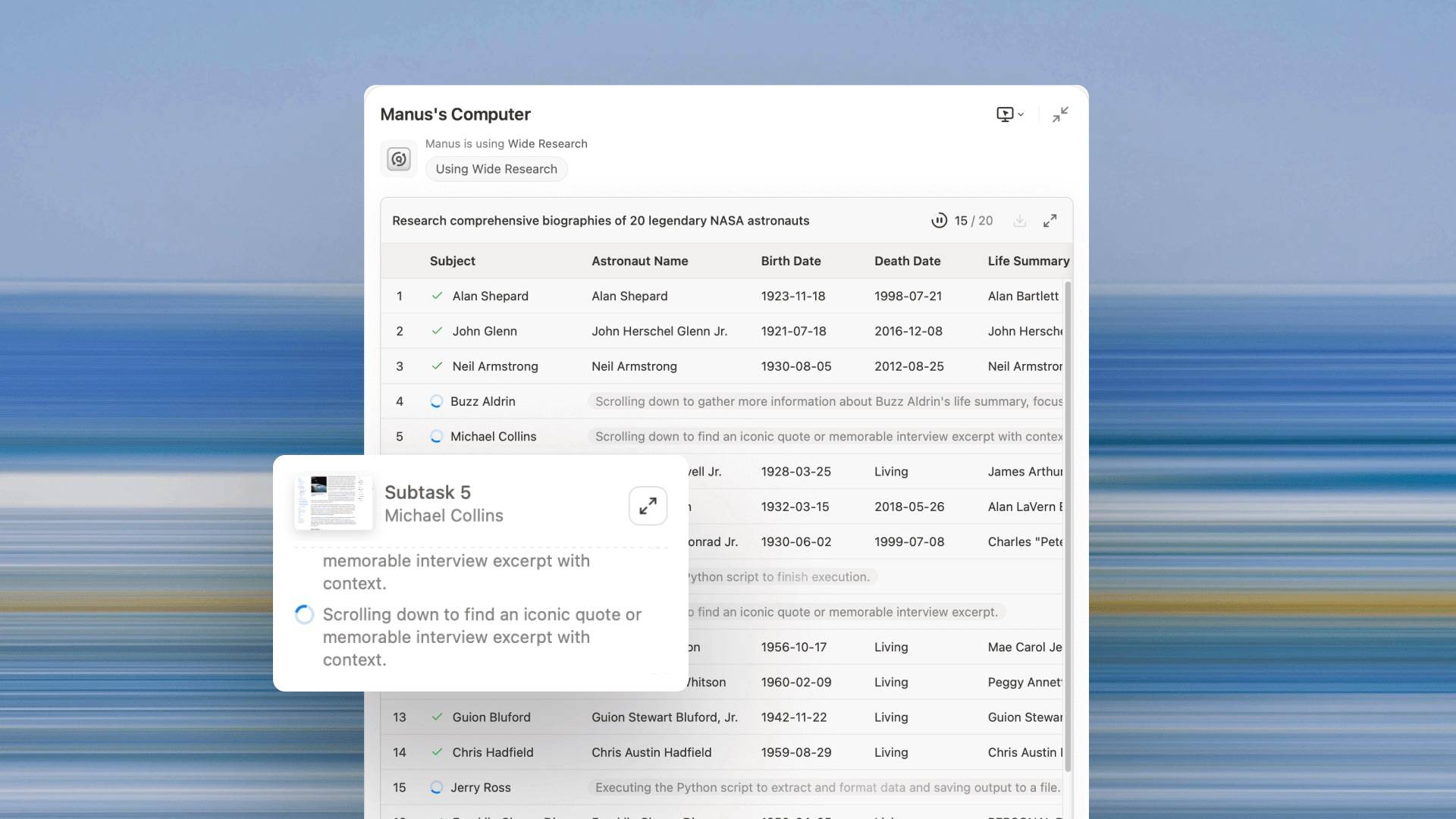
昨晚,Manus 正式推出一项新功能,能够通过协调数十个 AI 智能体进行同时工作,以实现广泛研究,并命名为「Wide Research」(广泛研究)。
官方介绍,Wide Research 的关键不仅仅在于拥有更多的智能体——而是它们如何协作。与传统的基于预定义角色(如「管理者」「编程者」「设计师」)的多智能体系统不同,Wide Research 中的每个子智能体都是一个功能完备的、通用的 Manus 实例。
据悉,在 Wide Research 加持下,Manus 解锁了一种强大的新方式,让用户能够处理需要获取数百个项目信息的复杂、大规模任务。「无论您是在探索财富 500 强企业,比较顶尖 MBA 项目,还是深入研究 GenAI 工具,Wide Research 都使深入、大量的研究变得毫不费力。」
Wide Research 即日起正式向 Pro 用户推出,并计划逐步向 Plus 和 Basic 层级用户开放。
租电 17.98 万元起,乐道 L90 正式开售

昨晚,乐道 L90 正式上市,先看售价:
乐道 L90 六座版 Pro,整车购买售价为 26.58 万元,采用 BaaS 电池租用方案的售价则为 17.98 万元;六座版 Max,整车购买售价为 27.98 万元,BaaS 方案售价为 19.38 万元;六座四驱 Ultra 版 ,整车购买售价为 29.98 万元,BaaS 方案售价为 21.38 万元。
来看新车:17.98 万元起!乐道 L90 正式开售,还多了一个七座版本
尺寸方面,乐道 L90 车长 5145mm,轴距达到 3110mm。同时,其还拥有容积达 240L 的智能电动前备箱。在座舱内部,L90 还正式推出了大七座(2+3+2)版本。(价格为 27.18 万元起,BaaS 租电为 18.58 万元起)
在驾乘体验层面,L90 全系标配静音电吸门;动力系统提供两种配置,后驱版搭载 340kW 电机,四驱版综合功率则达到 440kW,百公里加速时间为 4.7 秒。
另外,新车底盘用上了前双叉臂后五连杆悬架,并配备拥有 100mm 调节行程的空气悬架;蔚来自研的「行云智享底盘」系统还可以根据云端数据,预判路况并提前调节悬架。
智能化层面,L90 的座舱采用四屏布局,搭载高通骁龙 8295P 芯片;35 英寸的 AR-HUD 支持 AR 增强显示,并可在转向时显示 16.7 英寸的盲点影像。辅助驾驶硬件上,标配了包括 4D 毫米波雷达在内的 30 个高性能感知硬件,为其全场景 NOA 领航辅助功能提供了支持。
续航上,新车通过轻量化车身、0.25Cd 的低风阻和高效热管理系统,在标配 85kWh 电池包的情况下,官方公布的百公里电耗为 14.5 度电,CLTC 综合续航为 605 公里。

网易云音乐起诉 SM 娱乐
据企查查消息,法院日前公开杭州乐读科技有限公司、杭州网易云音乐科技有限公司起诉 SM ENTERTAINMENT CO. 、卡斯梦(上海)文化传播有限公司等开庭信息,案由涉及滥用市场支配地位纠纷。
公告显示,该案件计划将于 8 月 6 日,在浙江省杭州市中级人民法院开庭审理。
据悉,今年 1 月,网易云音乐曾发布致韩国 SM 歌迷的一封信,告知各位歌迷朋友因版权方单方面通知不续约,并表示在 2025 年 1 月 31 日以后,平台很可能不得不下架韩国 SM 娱乐公司旗下全部歌曲内容。网易云方面会争取版权续约的可能,如果有进一步的消息会第一时间告知用户。
值得一提的是,今年 5 月,腾讯音乐通过场外大宗交易方式,斥资 12.9 亿元成为 SM 娱乐二股东后,其在 K-pop 版权市场的话语权显著增强,甚至可能进一步压缩网易云音乐的版权空间。
另据法院公开,深圳市腾讯计算机系统有限公司、腾讯音乐娱乐(珠海)有限公司起诉广州网易计算机系统有限公司、杭州乐读科技有限公司、杭州网易云音乐科技有限公司,案由涉及不正当竞争纠纷,同样也计划将于 8 月 6 日,在浙江省杭州市中级人民法院开庭审理。
「鼠标手」被纳入职业病
据 IT 之家消息,国家卫生健康委等 4 部门联合印发新版《职业病分类和目录》,由原有的 10 大类 132 种职业病增加到 12 大类 135 种职业病,并将于 2025 年 8 月 1 日起正式实施。
目录新增 2 个职业病类别,分别为职业性肌肉骨骼疾病、职业性精神和行为障碍,每个类别中分别新增 1 种职业病。
其中,职业性肌肉骨骼疾病类别中新增腕管综合征,职业性精神和行为障碍类别中新增创伤后应激障碍(限于参与突发事件处置的人民警察、医疗卫生人员、消防救援等应急救援人员)。
据悉,腕管综合征即俗称的「鼠标手」,本次被纳入新版《职业病分类和目录》,但只限于长时间腕部重复作业或用力作业的制造业工人。
目录要求 2025 年底前,每个省份至少有 2 家以上机构可提供新增职业病的检查、诊断及康复服务,保障劳动者健康权益。
小红书 RED LAND 将登陆上海复兴岛

据人民网报道,8 月 8 日至 10 日,小红书 RED LAND 开放世界冒险岛活动将登陆位于杨浦区的复兴岛,上海杨浦复兴岛将变身为全球首座二次元「痛岛」。
RED LAND 活动期间,复兴岛上的 8 万平米空间将因地制宜,与经典的游戏、二次元动漫场景有机结合,为游戏二次元爱好者带来沉浸式游玩体验。
据悉,位于杨浦区的复兴岛面积约 1.3 平方公里,是上海黄浦江畔唯一的内陆岛屿,也是规划中一块罕见的「留白」地。2024 年 12 月 13 日,上海量子城市时空创新基地落地复兴岛,开启了书写复兴岛全新的故事篇章。

史努比动画音乐剧定档 8 月上线

据守望好莱坞消息,史努比&花生漫画改编近 35 年来的首部音乐剧——特别集《Snoopy Presents: A Summer Musical》发布预告。
该剧将讲述查理·布朗热爱露营,决心让自己的最后一年过得特别。但第一次参加露营的莎莉却对这个陌生的新地方感到紧张和疑虑。就在大家安顿好营地时,史努比和伍德斯托克发现了一张藏宝图,这张地图指引他们踏上附近的野外探险之旅。
影片由 Erik Wiese 导演,艾蒂安·凯利奇、Jayd Deroché 配音,将于 8 月 15 日上线 Apple TV+。
《哪吒 2》明日全网上线

昨日,电影《哪吒之魔童闹海》宣布,将于 8 月 2 日 10 点上线国内多个视频网站。
据悉,本次《哪吒之魔童闹海》将登陆哔哩哔哩、腾讯视频、爱奇艺、优酷等多个网站。其中,据腾讯视频表示,《哪吒之魔童闹海》在腾讯视频站内预约量冲破 1246 万,登上站内电影预约榜单 TOP1。
《哪吒之魔童闹海》于今年 1 月 29 日上映,全球累计总票房达到 159.11 亿元,位居全球影史票房榜第五位。
《纽伦堡》首曝预告,11 月上映

据守望好莱坞消息,电影《纽伦堡》预告公布,并定档 11 月 7 日北美上映。
影片改编自《纳粹与精神病医生》,聚焦二战结尾,纽伦堡法庭对德国劳工阵线领导人罗伯特·莱伊的审判(其后来在狱中自杀),以被委任来对纳粹头领们进行评估的美军精神科医生 Douglas Kelley 的视角展开。
该片由詹姆斯·范德比尔特执导并编剧,罗素·克劳、拉米·马雷克、利奥·伍德尔、迈克尔·珊农主演,另外还将于 2025 年 9 月 6 日在多伦多国际电影节首映。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
from 爱范儿 https://ift.tt/TbRkhNX
via IFTTT