
天下苦 OpenAI 挤牙膏久矣。
环顾宇内,能够与 OpenAI 抗衡的对手屈指可数,Anthropic 旗下的 Claude 模型至少算是一个靠谱的劲敌。
盼星星,盼月亮,没有等到「超大杯」Opus 的亮相,但好在也等来了全新升级的大杯 Claude 3.5 Sonnet。
简单总结这次更新的亮点:
- 拳打 GPT-4o,脚踢 Gemini 1.5 Pro,新版 Claude 3.5 Sonnet 表现遥遥领先
- Claude 3.5 Haiku 响应速度最快,性能媲美 GPT-4o mini
- 构建 API,教 Claude 怎么玩电脑
教 Claude 玩电脑,AI 键盘侠来了?
这次更新的重头戏其实不是新模型,而是怎么教 AI 玩电脑。
Anthropic 推出了一个公开测试的革命性功能「computer use」:通过 API 教 Claude 像个人一样操作电脑,能看屏幕、动光标、点按钮、打字……
简单说就是,Claude 现在能用人类设计的标准工具和软件了。而开发者可以借此解放一些枯燥的重复性流程任务,甚至进行开放式任务,如研究。
为了让 Claude 具备这种技能,Anthropic 通过一个 API 来让 Claude 能够感知并与计算机界面交互。
具体来说,开发者在交互过程中集成这一 API,让 Claude 将指令(比如:「用我电脑上的数据,结合网上信息填个表」)翻译成计算机指令(比如:检查个表格,动动鼠标打开个浏览器,导航到相关网页,然后用网上的数据把表格填满)。
OSWorld 是一个用于测试多模态智能体在真实计算机环境中执行开放式任务的能力的基准测试平台,通常用来评估 AI 模型是否具备像人类一样使用计算机的能力。
Claude 3.5 Sonnet 在仅用截图的测试类别中得分 14.9%,远超第二名的 7.8%。在允许使用更多步骤时,Claude 的得分为 22.0%。
一些公司的产品已经提前用上了这一功能。
例如,Replit 正在利用 Claude 3.5 Sonnet 的计算机操作与界面导航能力,为其 Replit 智能体产品开发一项关键功能,用于评估正在构建中的应用程序。
当然,这种做法其实并不新鲜。
因为在此之前,Asana、Canva、Cognition、DoorDash、Replit 和 The Browser Company 已经开始探索这些可能性,执行需要几十甚至上百步的任务。
不过,理想很丰满,现实很骨感。
官方也坦诚,当前这一功能仍处于实验阶段,在操作计算机时速度较慢,并且经常会出现错误。一些简单的操作——比如滚动、拖动、缩放,看似人类一挥手就能搞定的事儿,对 Claude 来说依然是个不小的挑战。
在录制这些演示的过程中,我们遇到了一些有趣的插曲。有一次,Claude 不小心终止了一个正在进行的长时间屏幕录制,结果所有的录像素材都丢失了。
之后,Claude 在我们的编码演示间隙休息了一下,开始欣赏黄石国家公园的照片。
此外,Claude 通过截取屏幕的静态图像,然后将这些图像组合起来,以理解屏幕上发生的事情,但也正因此,它可能无法捕捉到屏幕上的短暂动作或通知,比如弹出窗口或快速变化的图标。
官方也说了,之所以提前发布一个实验品,是为了获取开发者的反馈,预计这功能随着时间会逐渐有所改进。
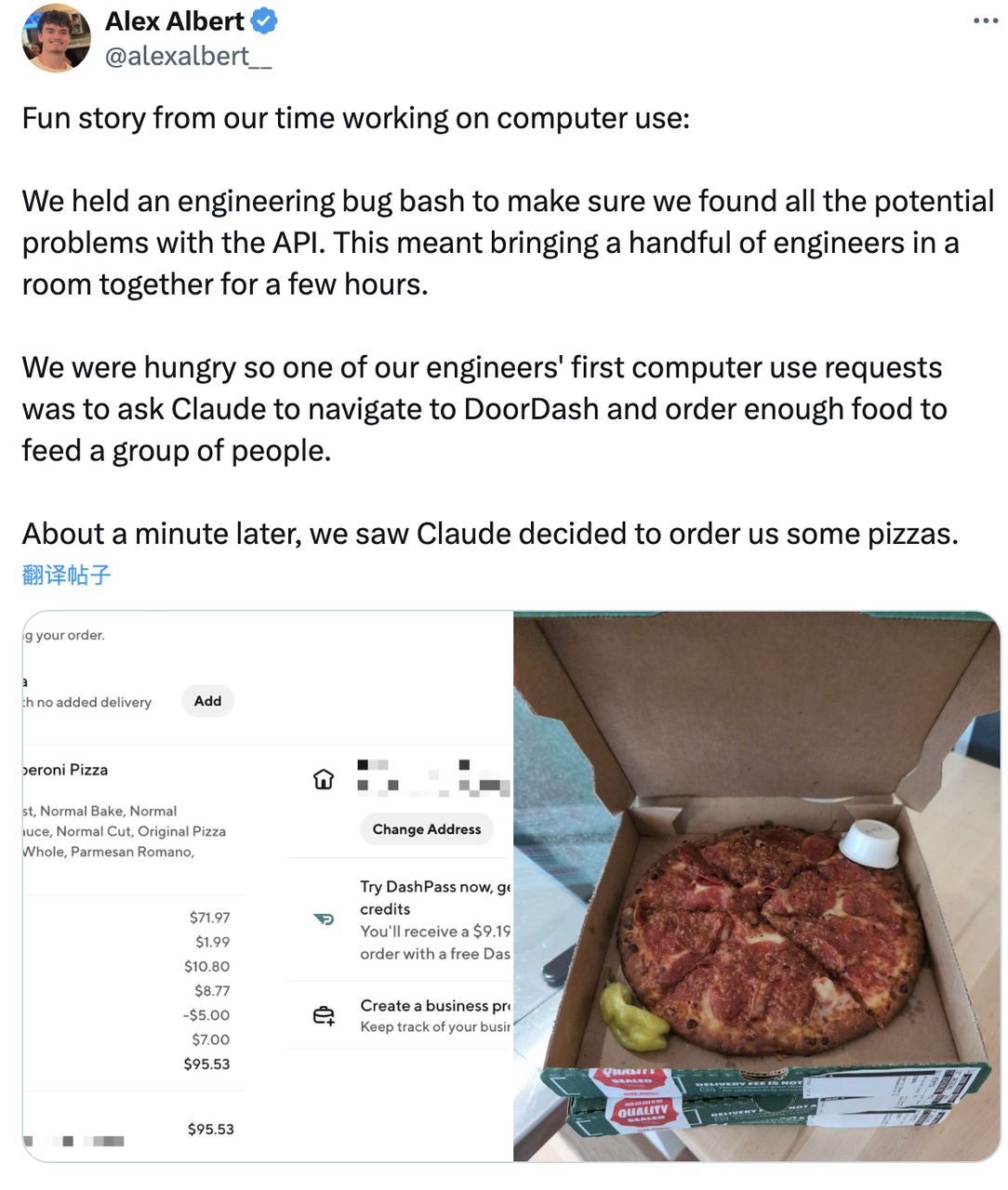
Anthropic 开发者关系主管 Alex Albert 还分享了一个有趣的经历。
在开发「computer use」功能时,他们组织了一次工程故障排查会,目的是找出 API 中所有潜在的问题。
几位工程师聚在一个房间里工作几个小时,但很快就饿了,所以其中一位工程师的第一个「computer use」请求是让 Claude 导航到外卖平台 DoorDash 并订购足够的食物来喂饱大家。
Claude 思考了大约一分钟后, 最后给工程师们订了几份披萨。
网友也很快挖出了 computer use 功能拒绝做的清单:
- 在社交媒体或其他平台上创建账户
- 发送电子邮件或消息
- 在社交媒体上发布评论
- 进行购买
- 访问私人信息
- 完成验证码(CAPTCHA)
- 生成、编辑或修改图片
- 打电话
- 访问受限内容
- 执行需要个人身份验证的操作

真·推理模型之王,新模型编码遥遥领先
再来看看 Claude 3.5 Sonnet 交出的成绩单。
尽管现在大模型榜单的公信力已不如往日,但基于同一套考题的逻辑下,我们仍然能对新发布的模型有个初步了解。
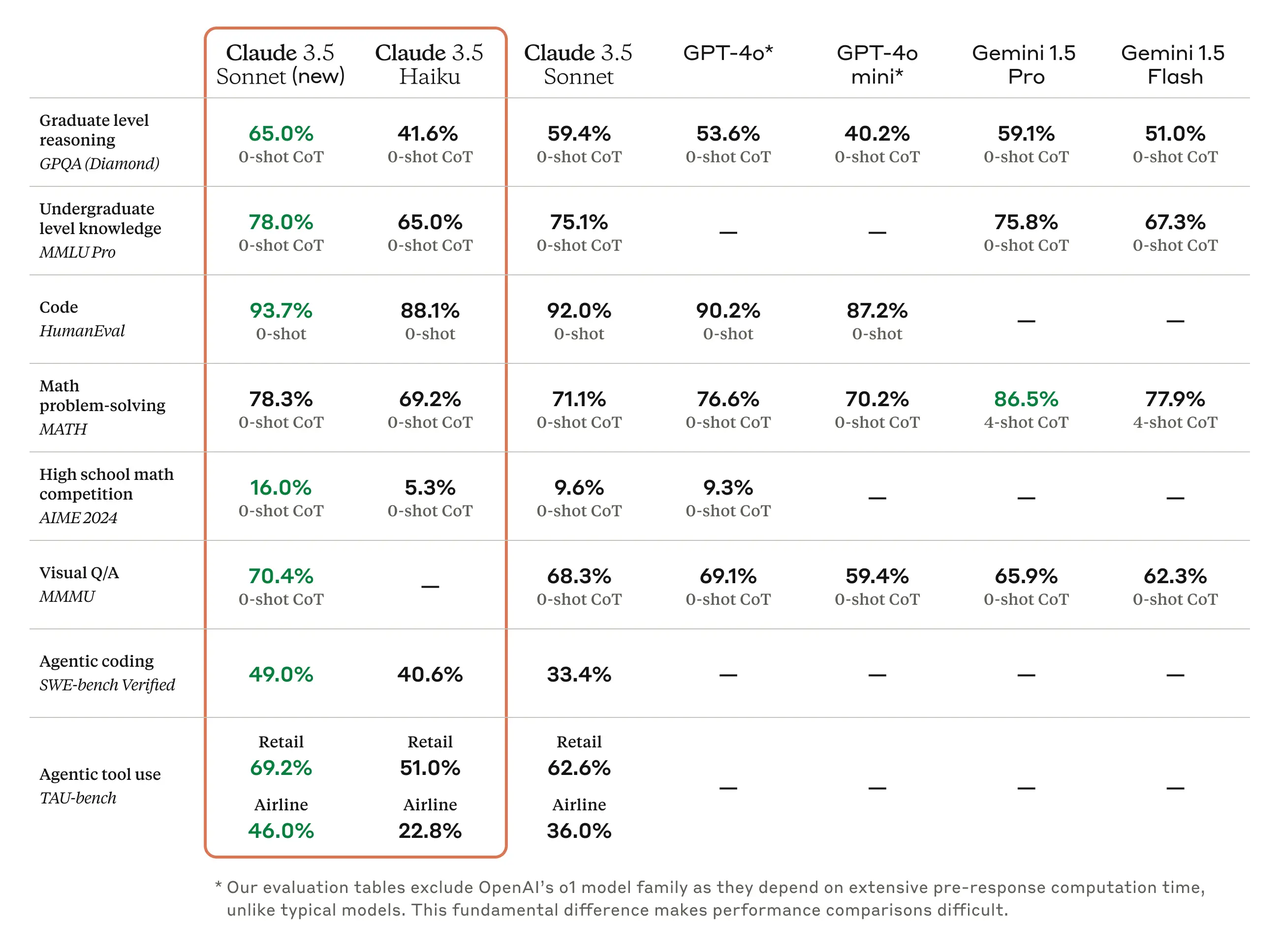
拳打 GPT-4o,脚踢 Gemini 1.5 Pro,Claude 3.5 Sonnet 在 GPQA、MMLU Pro、HumanEVal 等一系列基准测试中表现亮眼,可谓是遥遥领先。
特别是在编码领域,Claude 3.5 Sonnet 更是进一步拉大了领先优势。或许你会好奇,为什么基准测试里没有出现与 OpenAI o1 模型的对比。
别急,Anthropic 预判了你的预判,官方给出的解释是:
我们的评估表格中之所以没有包含 OpenAI 的 o1 模型系列,是因为它们在响应前需要大量的计算时间,这与大多数模型不同。这种本质上的区别使得进行性能比较变得复杂。
翻译一下就是,我们想比但也不好比。
不过,在 SWE-bench Verified 的编码测试中,Claude 3.5 Sonnet 的表现从 33.4% 提升到 49.0%,超过了所有公开可用的模型——包括 OpenAI o1-preview 等推理模型,以及各种智能体编码系统。
Claude 3.5 Sonnet 真·推理模型之王。
此外,在 TAU-bench 智能体工具测试中,Claude 3.5 Sonnet 也表现不俗。
TAU-bench 主要提供一个更接近真实世界应用场景的评估环境。
面对零售领域问题,Claude 3.5 Sonnet 得分从 62.6% 提高至 69.2%,而面对航空方面的问题,其成绩也从 36.0% 上升至 46.0%。

更重要的是,这些改进并未提高价格或降低速度,Claude 3.5 Sonnet 仍保持了与前代相同的性价比。
官方博客中提到,编码能力的改进是 Claude 3.5 Sonnet 的最大亮点。
GitLab 测试发现其推理能力提升了 10%,无额外延迟,非常适合多步骤的软件开发流程。The Browser Company 也指出,Claude 3.5 Sonnet 在自动化网页工作流程方面的表现超越了他们之前测试的所有模型。
作为追求极高安全系数的模型公司,Anthropic 自然也对 Claude 3.5 Sonnet 进行了灾难性风险评估,结果符合 ASL-2 标准。。
ASL-2 指的是显示出危险能力早期迹象的系统(例如能够给出如何制造生物武器的指令),但这些信息由于可靠性不足或无法超越搜索引擎能提供的信息而没有太多用处。
简言之,Claude 3.5 Sonnet 再强,也还没有到威胁人类的地步。
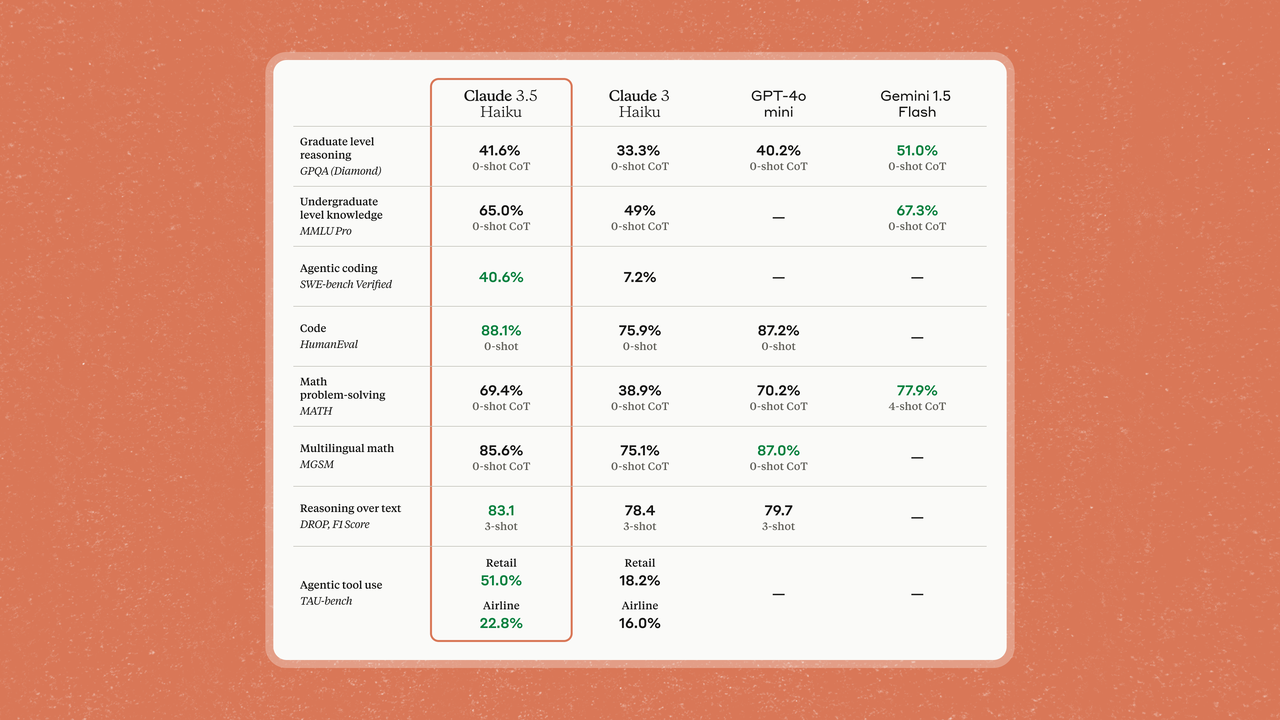
聊完性能最强的模型,接下来登场的是,响应速度最快的全新升级模型——Claude 3.5 Haiku。
光看纸面参数,中杯 Claude 3.5 Haiku 几乎不逊色于 GPT-4o mini,甚至可以说,它已经可以小赢一把,整体表现也与前代 Claude 3 Opus 表现持平。
但价格没变,响应速度也没减,有种「加量不加价」的错位体验。
类似地,Claude 3.5 Haiku 在在编码任务的表现也尤为突出。例如,它在 SWE-bench Verified 上的得分为 40.6%,超过了很多所谓的最先进智能体,包括它的 Claude 3.5 Sonnet(原版)和 GPT-4o。
低延迟、改进的指令执行能力以及更精准的工具使用能力,这些特性都让 Claude 3.5 Haiku 尤其适用于需要个性化服务的场景中。
比如根据你以前买东西的习惯来推荐商品,或者帮你决定商品的价格,甚至是帮你管理仓库里的存货。
最后,升级版的 Claude 3.5 Sonnet 现已面向所有用户开放。而 Claude 3.5 Haiku 将于本月晚些时候发布,初期只支持文本输入,图像输入功能随后推出。

如果你最近关注 AI 圈,你会发现行业里的几位重要人物都玩起了「未卜先知」。
Demis Hassabis、Yann LeCun、Sam Altman 和 Anthropic 的 Dario Amodei,都宣称 AGI 将在未来几年内实现,时间范围从 2025 年到 2030 年不等。
他们画了一张又一张堪比乌托邦的 AGI 蓝图,如治愈大多数疾病、解决气候问题、消除贫困等,如果汇总几篇长文的核心思想,AI 几乎成了包治百病的神药。
但话说回来,信心还得是靠真刀真枪的产品来证明。
在没有可靠、可持续的商业模式下,这个行业只能靠对 AGI 的「盲信」来维持高昂的投资和支出,就好像挂在驴前面的那根晃荡的萝卜。
换言之,今天发布的 Claude 模型等一系列产品功能也是在让我们重拾信心,而按照以往的产品发布节奏,OpenAI 预计也快要出手了。
不同之处在于,OpenAI 的武器库显然更丰富。或许下一个亮相的会是 OpenAI o1 的正式版,又或者是「期货」Sora。
接下来,我们就拭目以待,看 OpenAI 如何「亮剑」了。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
from 爱范儿 https://ift.tt/BZVsrqD
via IFTTT
没有评论:
发表评论