今年的 CES 黄仁勋主题演讲上,罕见的,他没有介绍英伟达的消费级显卡。
目前最新的消费级 GPU,还是去年在 CES 上正式发布的 RTX 50 系列。其中必然有内存全球大涨价的原因,当前市场的内存成本,一周之内就能涨价 50%-100%,并且多个分析机构表示,涨价会持续到 2027 年。
更多的原因还是 AI,就拿 AI 训练和部署来说。一块 RTX 5090 显卡的最大显存是 32GB,随便找一个表现不错的开源大模型,参数都是以百亿为单位,所需要的显存容量,32G 的优势会比较有限。

但英伟达显然不会放弃本地计算的市场,今年不发消费级的显卡,有了全新的消费级个人超算。
英伟达在 CES 2026 上展示了全新的 DGX Spark,并且用它完成了多个 AI 相关的任务。开发者和创作者不需要昂贵的数据中心,通过 DGX Spark,就可以在本地流畅运行、微调,甚至推理高达 100B 参数的前沿 AI 模型。
我们之前也分享过 DGX Spark 的上手体验,下载 1200 亿参数的 GPT-OSS 开源模型,或者部署 Qwen 图片生成、Wan 2.2 视频生成,DGX Spark 都能做到。
再回顾一下 DGX Spark 的主要情况。

- 核心架构:基于 NVIDIA Grace Blackwell 架构打造,将数据中心级别的 AI 算力,浓缩到了紧凑的桌面机箱中。
- 海量内存:单机配备 128GB 统一内存。更为独特的是,它支持通过 200Gbps 的 ConnectX-7 网络,将两台 DGX Spark 互连,组成拥有 256GB 内存的超级节点。
- 核心能力:专为大模型时代设计,支持在本地运行 100B 参数级别的模型,或者对 70B 参数的 LLM 进行分布式微调。
- 定位:它不仅是开发者的沙盒环境,而且还要做 AI 创作者的平台,主要是让高强度的 AI 工作负载,脱离云端依赖,在本地安全、低延迟地完成。
本次 CES 更新的最大亮点,在于通过软件升级引入了对 NVFP4 数据格式的全面支持。NVFP4 的数据格式,能够让新一代模型在保持智能表现的同时,内存占用降低约 40%,吞吐量大幅提升。
具体的实测数据,在两个 DGX Spark 配置上运行 Qwen-235B 模型时,使用 NVFP4 相比 FP8 性能提升最高可达 2.6 倍。这直接地解决了,过去使用 FP8 精度时双系统内存耗尽、无法多任务处理的难题。
硬件在桌面上,但访问方式可以很云端。CES 上展示的 Brev 更新,还解决了 DGX Spark 本地算力灵活性不足的问题。
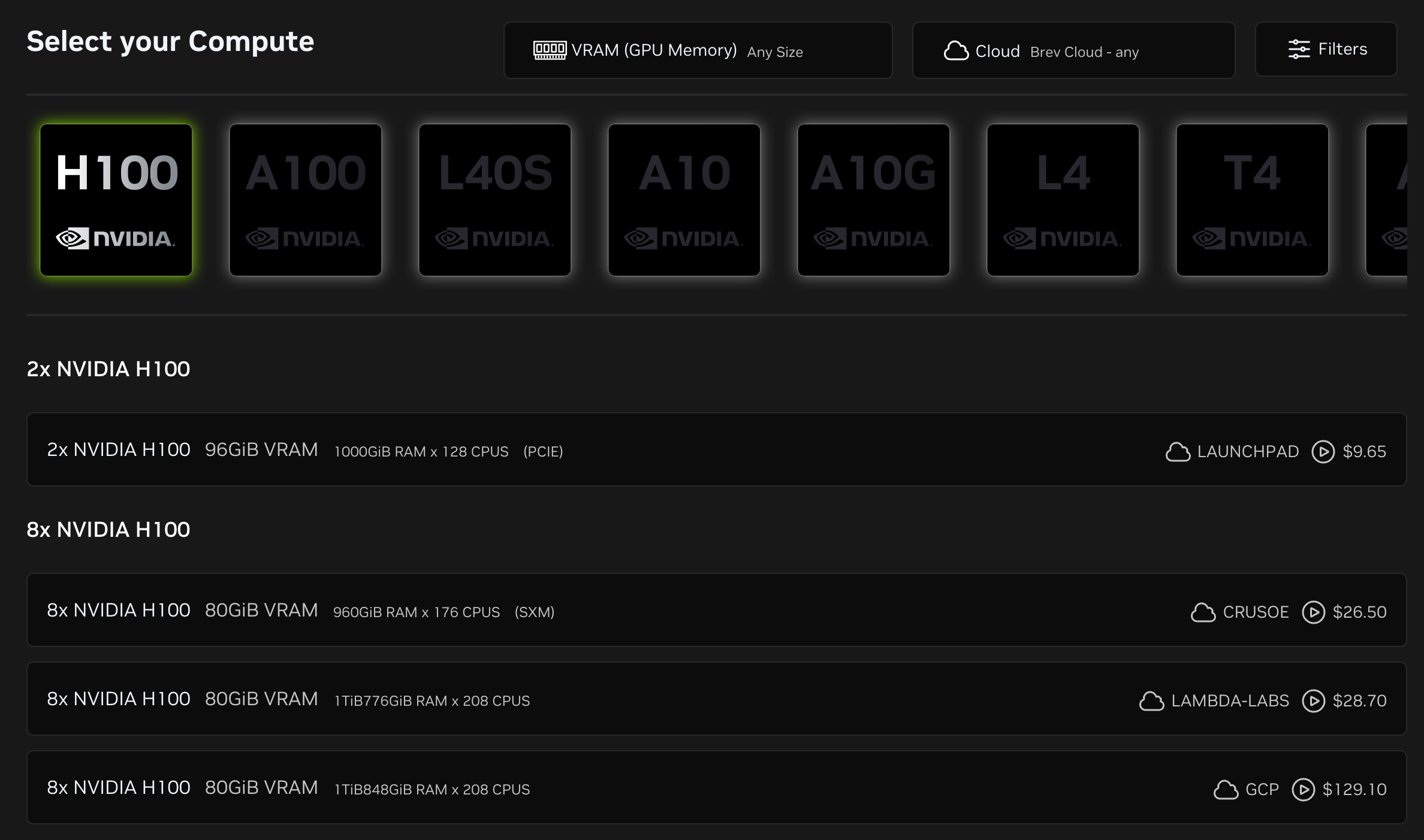
现在,开发者可以通过 Brev,安全地远程连接 DGX Spark,就像使用云服务一样便捷。此外,Brev 支持智能路由层。用户可以将处理邮件或专有数据等敏感任务,强制保留在本地 DGX Spark 上运行,而将一般推理任务无缝路由至云端,兼顾了隐私安全与云端算力。
Brev 的引入,解决了本地算力不仅能用,还要好用的问题。它的本地计算支持预计于 2026 年春季正式推出。
这么强的算力能用来做什么,英伟达在 CES 现场的演示也给出了答案。
对于视频创作者,这是强大的创意生成加速器。将 AI 视频生成任务从笔记本转移到 DGX Spark 上,相比顶配 M4 Max 的 MacBook Pro,速度实现了高达 8 倍的提升,真正做到了让创作流不再卡顿。
不仅是个人开发者,对于注重本地安全的企业用户,DGX Spark 也能胜任。英伟达展示了由 Nsight 驱动的本地 CUDA 编码助手,企业开发者可以在享受 AI 辅助的同时,确保源代码完全存储在本地,杜绝信息泄露风险。
更有意思的演示是和机器人的结合。通过与 Hugging Face 的合作,DGX Spark 化身 Reachy Mini 机器人的「大脑」,让机器人具备了实时视听交互能力。现在看起来,用 DGX Spark 来做具身智能,也不再是大厂的专属。
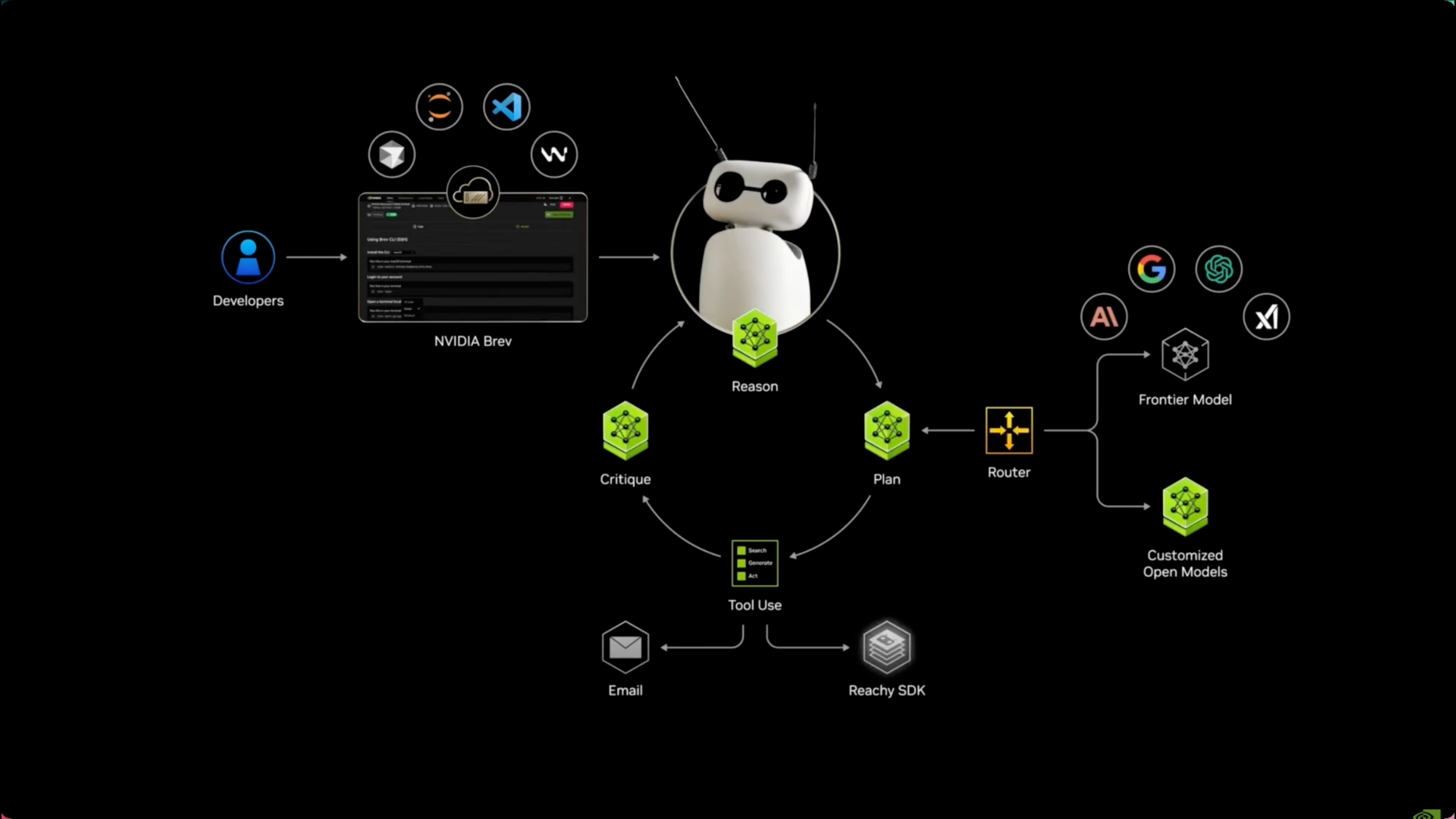
Hugging Face 产品副总裁 Jeff Boudier 也提到,「开放模型赋予开发者以自己的方式构建 AI ,而 DGX Spark 将这种能力带到桌面端……让强大的 AI 变成真正可以互动的存在。」

为了降低开发者的门槛,英伟达还在 CES 上一口气新增了 6 个 Playbook(实战手册),重点覆盖了当下的热门需求。
- Nemotron 3 Nano,英伟达最新的开源智能体大模型,用于本地 LLM 实验。
- Live VLM WebUI,实时视觉语言模型分析,通过输入网络摄像头画面,直接在 DGX Spark 本地进行视频分析。
- Isaac Sim / Lab,机器人仿真与强化学习。
- 双系统微调,展示了如何利用两台 DGX Spark,分布式微调 70B 参数的 LLM。
除了 Playbook 的更新,DGX Spark 还预装了经过优化的 NVIDIA AI 软件和 CUDA-X 库。这意味着开发者无需在繁琐的驱动配置,和环境依赖上浪费时间,开箱即可获得「即插即用」的优化能力,直接开始构建或微调 AI 模型。
DGX Spark 在 CES 2026 上的出现,意味着「大模型本地化」已经不再是一句空话。无论是为了数据安全、开发效率,还是为了探索下一代具身智能,DGX Spark 都在努力成为下一代 AI 应用构建的基座。
就像现在,已经开始有让 AI 来玩游戏的项目了,未来需要的,可能除了一块能流畅打《黑神话:悟空》的 5090,还会有更多的桌面级 AI 超级计算机出现。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
from 爱范儿 https://ift.tt/dVnWvA2
via IFTTT
没有评论:
发表评论