
AGI(通用人工智能)是整个 AI 行业的圣杯。
前 OpenAI 首席科学家 Ilya Sutskeve 在去年曾表达过一个观点:「只要能够非常好得预测下一个 token,就能帮助人类达到 AGI。」
图灵奖得主、被称为深度学习之父的 Geoffrey Hinton,OpenAI CEO Sam Altman 都认为 AGI 会在十年内,甚至更早的时间降临。
AGI 并非终点,而是人类发展史一个新的起点。在通往 AGI 的路上要考虑的事情还有很多,而中国的 AI 行业也是不可忽视的一股力量。
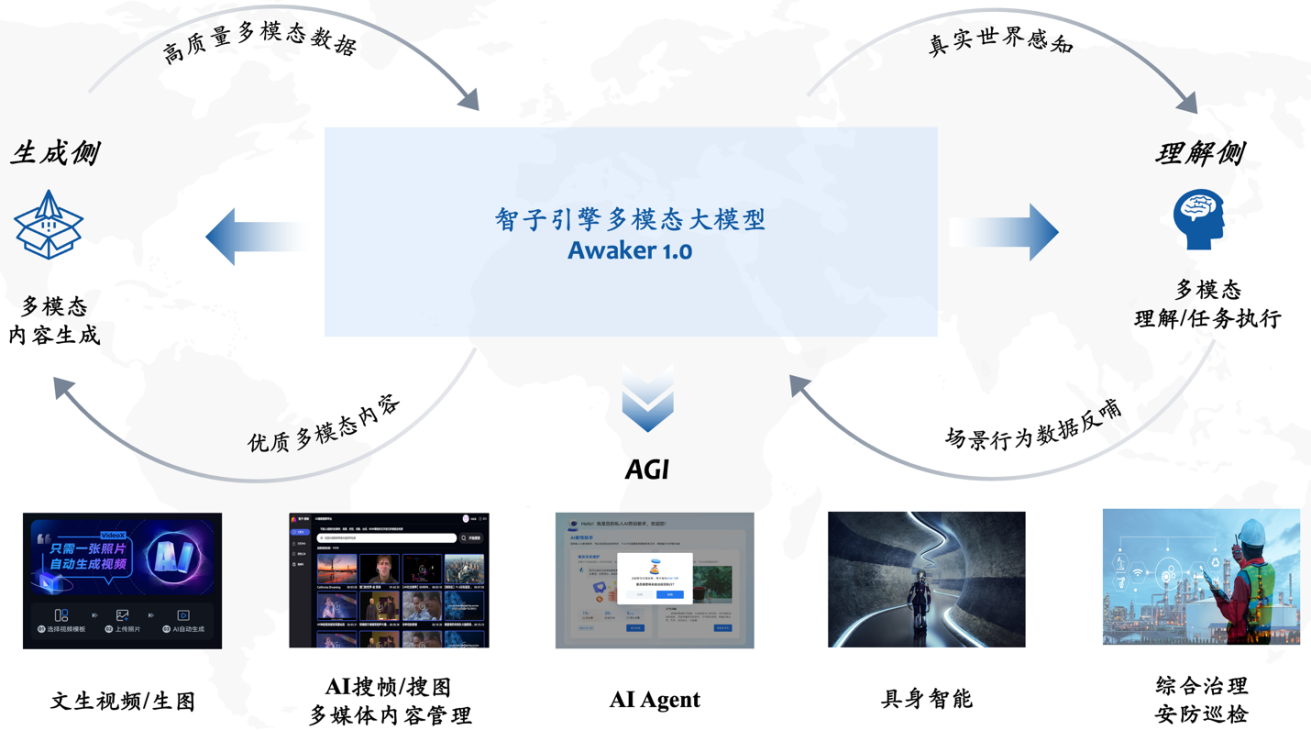
在 4 月 27 日召开的中关村论坛通用人工智能平行论坛上,人大系初创公司智子引擎隆重发布全新的多模态大模型 Awaker 1.0,向 AGI 迈出至关重要的一步。
相对于智子引擎前代的 ChatImg 序列模型,Awaker 1.0 采用全新的 MOE 架构并具备自主更新能力,是业界首个实现「真正」自主更新的多模态大模型。在视觉生成方面,Awaker 1.0 采用完全自研的视频生成底座 VDT,在写真视频生成上取得好于 Sora 的效果,打破大模型「最后一公里」落地难的困境。

Awaker 的 MOE 基座模型
在理解侧,Awaker 1.0 的基座模型主要解决了多模态多任务预训练存在严重冲突的问题。受益于精心设计的多任务 MOE 架构,Awaker 1.0 的基座模型既能继承智子引擎前代多模态大模型 ChatImg 的 基础能力,还能学习各个多模态任务所需的独特能力。相对于前代多模态大模型 ChatImg,Awaker 1.0 的基座模型能力在多个任务上都有了大幅提升。
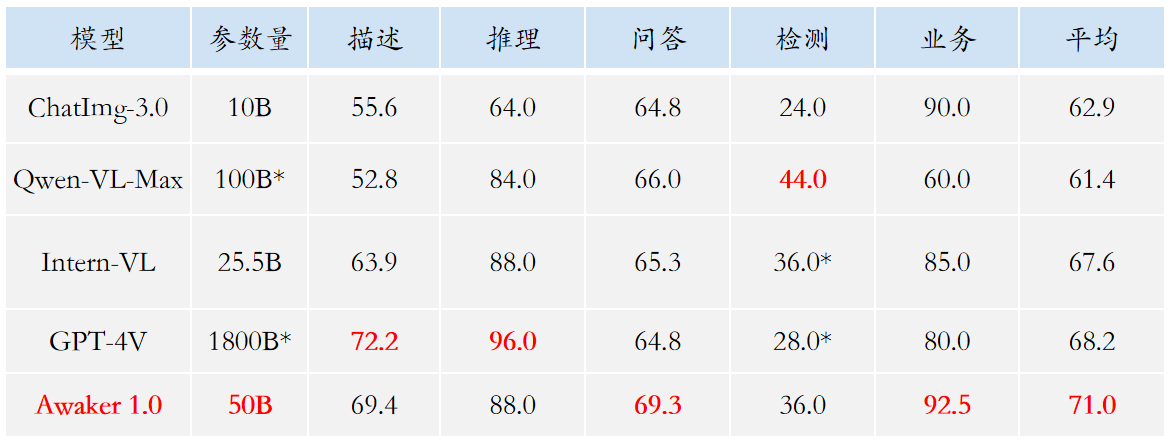
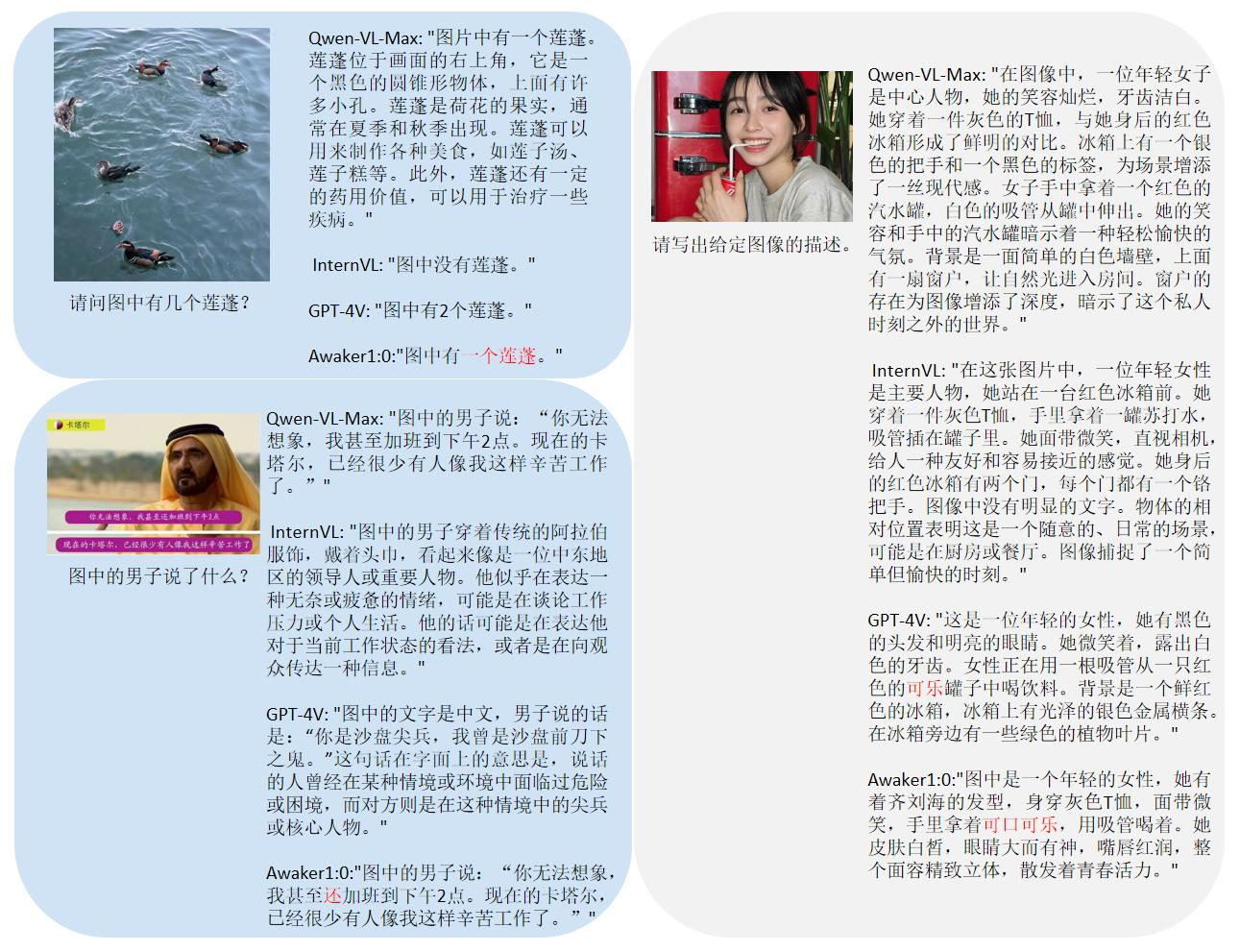
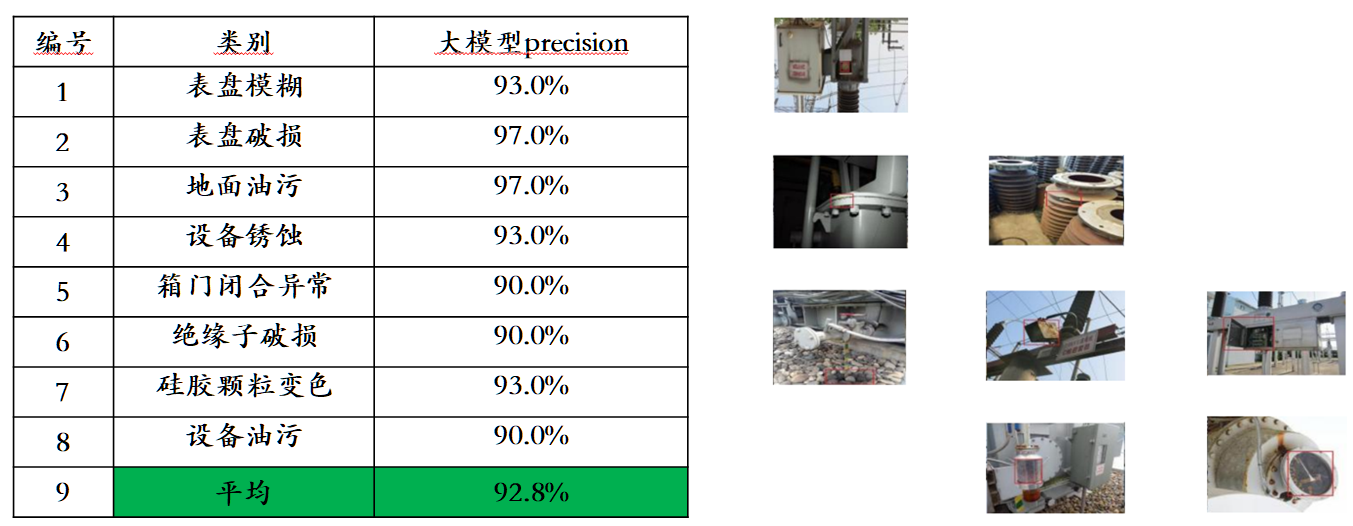
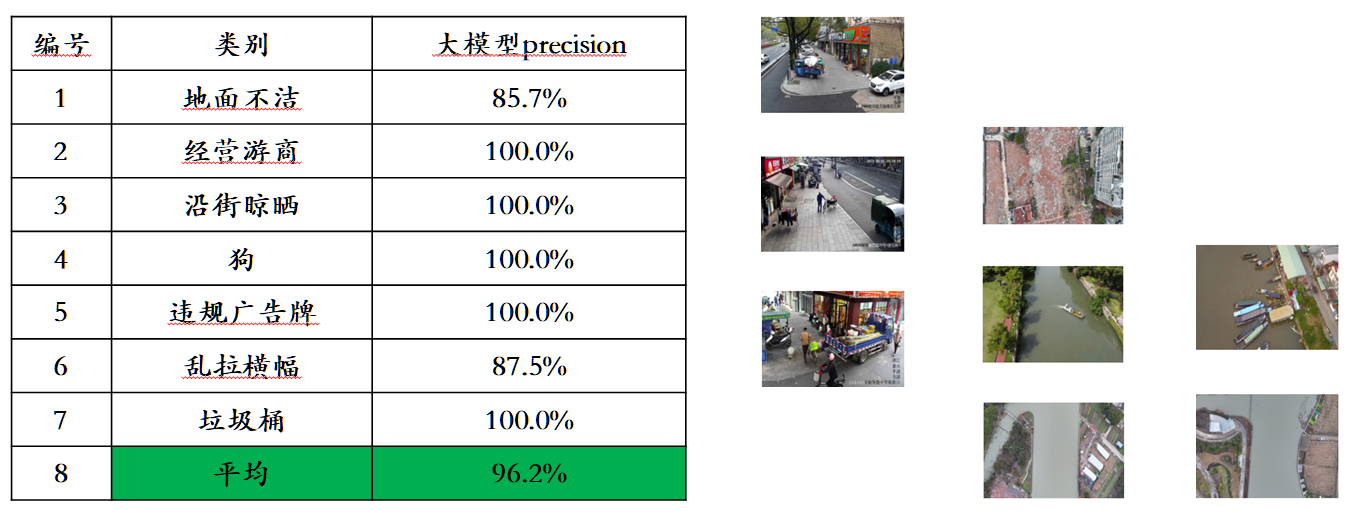
鉴于主流的多模态评测榜单存在评测数据泄露的问题,智子引擎披露了一个采取严格的标准构建自有的评测集,其中大部分的测试图片来自个人的手机相册。在该多模态评测集上,其对 Awaker 1.0 和国内外最先进的三个多模态大模型进行公平的人工评测,详细的评测结果如下表所示。注意到 GPT-4V 和 Intern-VL 并不直接支持检测任务,它们的检测结果是通过要求模型使用语言描述物体方位得到的。
Awaker+ 具身智能:迈向 AGI
多模态大模型与具身智能的结合是非常自然的,因为多模态大模型所具有的视觉理解能力可以天然与具身智能的摄像头进行结合。在人工智能领域,「多模态大模型+具身智能」甚至被认为是实现通用人工智能(AGI)的可行路径。
一方面,人们期望具身智能拥有适应性,即智能体能够通过持续学习来适应不断变化的应用环境,既能在已知多模态任务上越做越好,也能快速适应未知的多模态任务。另一方面,人们还期望具身智能具有真正的创造性,希望它通过对环境的自主探索,能够发现新的策略和解决方案,并探索人工智能的能力边界。通过将多模态大模型用作具身智能的「大脑」,有可能大幅地提升具身智能的适应性和创造性,从而最终接近 AGI 的门槛(甚至实现 AGI)。
但是,现有的多模态大模型都存在两个明显的问题:一是模型的迭代更新周期长,需要大量的人力和财力投入;二是模型的训练数据都源自现有的数据,模型不能持续获得大量的新知识。虽然通过 RAG 和长上下文的方式也可以注入持续出现的新知识,但是多模态大模型本身并没有学习到这些新知识,同时这两种补救方式还会带来额外的问题。总之,目前的多模态大模型在实际应用场景中均不具备很强的适应性,更不具备创造性,导致在行业落地时总是出现各种各样的困难。
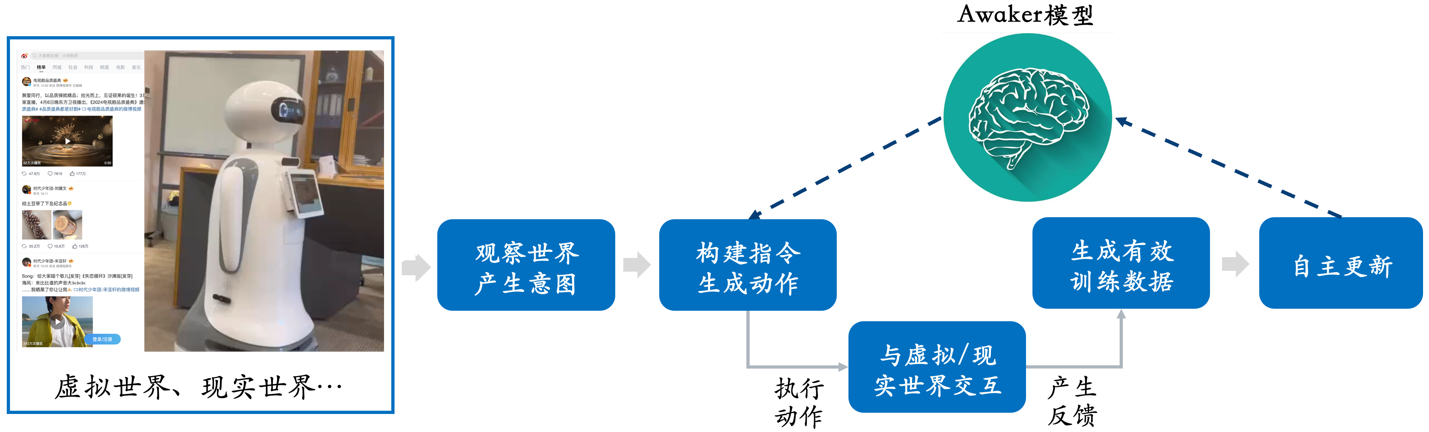
智子引擎此次发布的 Awaker 1.0,是世界上首个具有自主更新机制的多模态大模型,可以用作具身智能的「大脑」。Awaker 1.0 的自主更新机制,包含三大关键技术:数据主动生成、模型反思评估、模型连续更新。
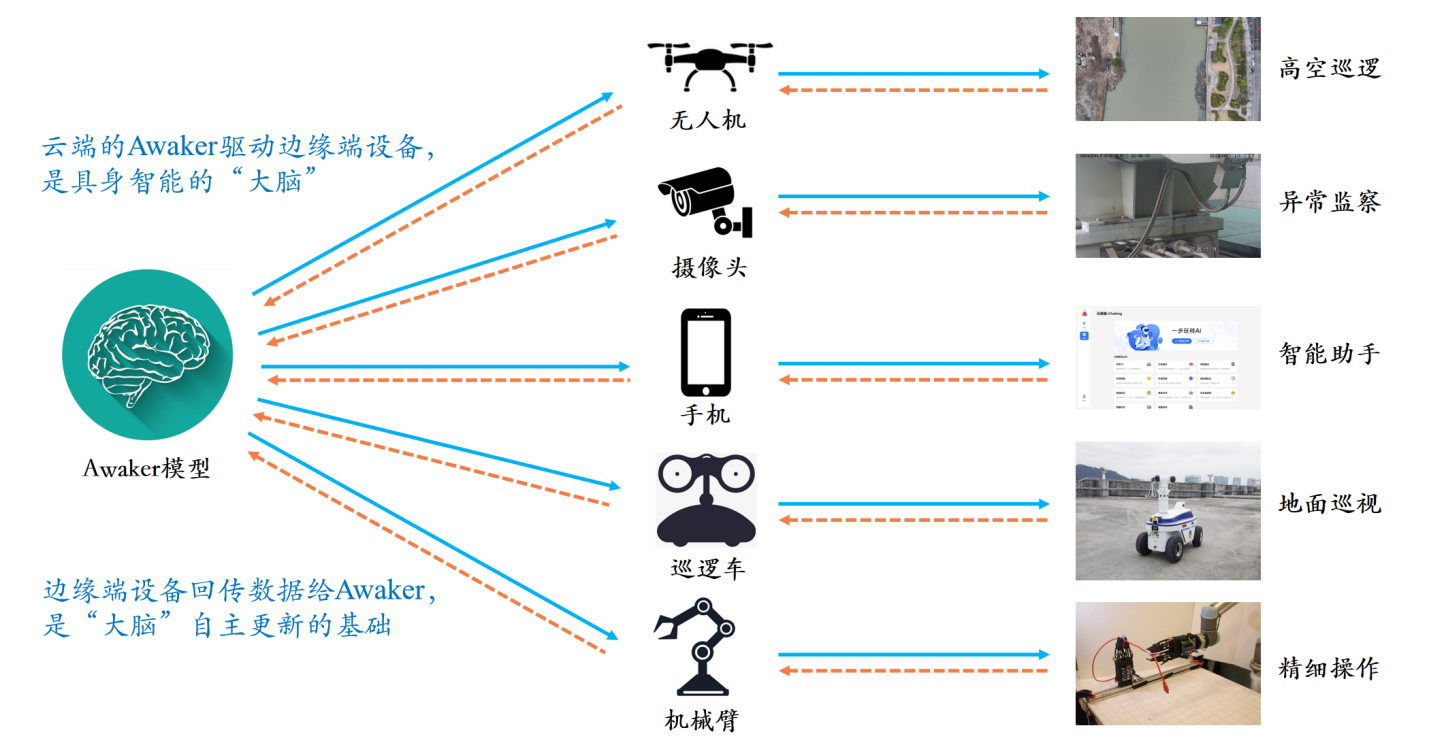
区别于所有其它多模态大模型,Awaker 1.0 是「活」的,它的参数可以实时持续地更新。从上方的框架图中可以看出,Awaker 1.0 能够与各种智能设备结合,通过智能设备观察世界,产生动作意图,并自动构建指令控制智能设备完成各种动作。智能设备在完成各种动作后会自动产生各种反馈,Awaker 1.0 能够从这些动作和反馈中获取有效的训练数据进行持续的自我更新,不断强化模型的各种能力。
以新知识注入为例,Awaker 1.0 能够不断地在互联网上学习最新的新闻信息,并结合新学习到的新闻信息回答各种复杂问题。不同于 RAG 和长上下文的传统方式,Awaker 1.0 能真正学到新知识并「记忆」在模型的参数上。

从上述例子可以看到,在连续三天的自我更新中,Awaker 1.0 每天都能学习当天的新闻信息,并在回答问题时准确地说出对应信息。同时,Awaker 1.0 在连续学习的过程中并不会遗忘学过的知识,例如智界 S7 的知识在 2 天后仍然被 Awaker 1.0 记住或理解。
Awaker 1.0 还能够与各种智能设备结合,实现云边协同。Awaker 1.0 作为「大脑」部署在云端,控制各种边端智能设备执行各项任务。边端智能设备执行各项任务时获得的反馈又会源源不断地传回给 Awaker 1.0,让它持续地获得训练数据,不断进行自我更新。
现实世界的模拟器:VDT
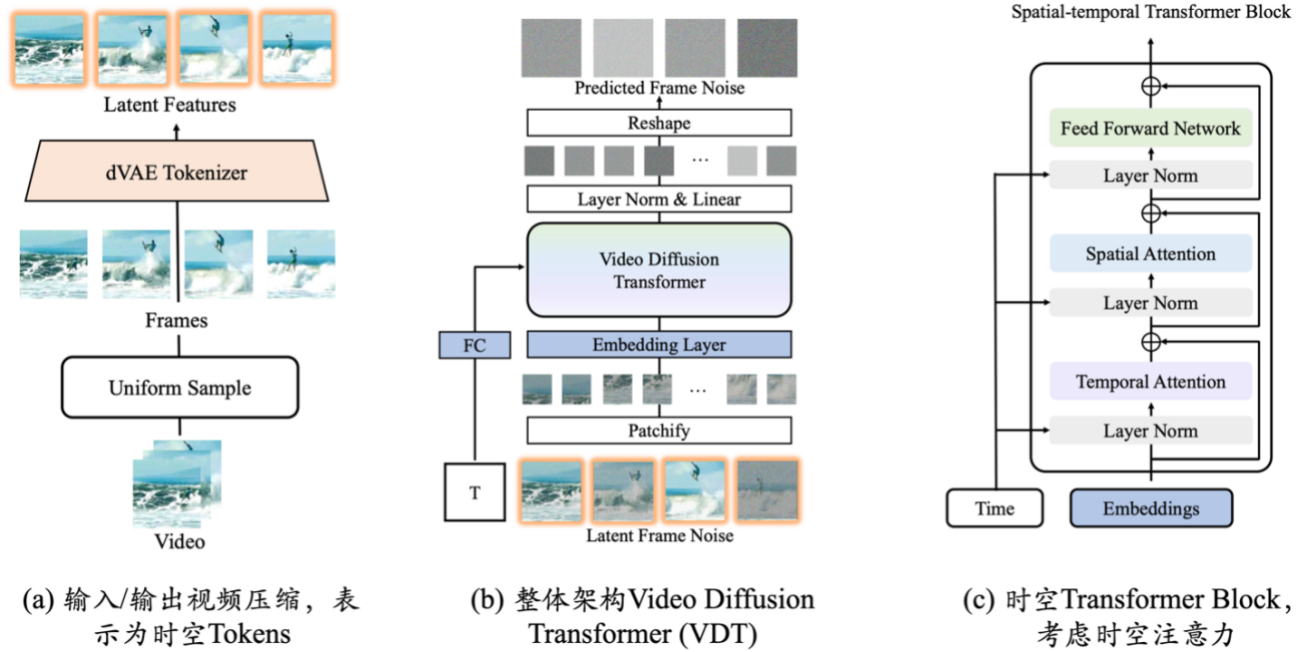
视频生成底座 VDT 的创新之处,主要包括以下几个方面:
- 将 Transformer 技术应用于基于扩散的视频生成,展现了 Transformer 在视频生成领域的巨大潜力。VDT 的优势在于其出色的时间依赖性捕获能力,能够生成时间上连贯的视频帧,包括模拟三维对象随时间的物理动态。
- 提出统一的时空掩码建模机制,使 VDT 能够处理多种视频生成任务,实现了该技术的广泛应用。VDT 灵活的条件信息处理方式,如简单的 token 空间拼接,有效地统一了不同长度和模态的信息。同时,通过与时空掩码建模机制结合,VDT 成为了一个通用的视频扩散工具,在不修改模型结构的情况下可以应用于无条件生成、视频后续帧预测、插帧、图生视频、视频画面补全等多种视频生成任务。
智子引擎团队重点探索了 VDT 对简单物理规律的模拟,在 Physion 数据集上对 VDT 进行训练。在下面的示例中,我们发现 VDT 成功模拟了物理过程,如小球沿抛物线轨迹运动和小球在平面上滚动并与其他物体碰撞等。同时也能从第 2 行第 2 个例子中看出 VDT 捕捉到了球的速度和动量规律,因为小球最终由于冲击力不够而没有撞倒柱子。这证明了 Transformer 架构可以学习到一定的物理规律。

他们还在写真视频生成任务上进行了深度探索。该任务对视频生成质量的要求非常高,因为我们天然对人脸以及人物的动态变化更加敏感。鉴于该任务的特殊性,研究人员需要结合 VDT(或 Sora)和可控生成来应对写真视频生成面临的挑战。目前智子引擎已经突破写真视频生成的大部分关键技术,取得比 Sora 更好的写真视频生成质量。智子引擎还将继续优化人像可控生成算法,同时也在积极进行商业化探索。目前已经找到确定的商业落地场景,有望近期就打破大模型「最后一公里」落地难的困境。
未来更加通用的 VDT 将成为解决多模态大模型数据来源问题的得力工具。使用视频生成的方式,VDT 将能够对现实世界进行模拟,进一步提高视觉数据生产的效率,为多模态大模型 Awaker 的自主更新提供助力。
结语
Awaker 1.0 是智子引擎团队向着「实现 AGI」的终极目标迈进的关键一步。智子引擎告诉 APPSO,团队认为 AI 的自我探索、自我反思等自主学习能力是智能水平的重要评估标准,与持续加大参数规模(Scaling Law)相比是同等重要的。
Awaker 1.0 已实现「数据主动生成、模型反思评估、模型连续更新」等关键技术框架,在理解侧和生成侧都实现了效果突破,有望加速多模态大模型行业的发展,最终让人类实现 AGI。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
from 爱范儿 https://ift.tt/aXCQEeg
via IFTTT
没有评论:
发表评论