
不管你有没有听过,OCR 技术已经渗入到我们生活中的方方面面。
不妨回想一下,汽车出入停车场时的车牌识别、金融业务开户时的银行卡识别、身份证识别、甚至是很多商务应用中的名片识别等,其实都是基于 OCR 技术的。

OCR 的发展可以追溯到 70 年代初,在数十年的发展中,OCR 的识别速度和识别成功率在不断地提高,应用场景也在不断地拓展。
从复杂背景中提取出文字、多种混合字体识别、低分辨率图像中识别、多语言混合是被、错行识别甚至是复杂多行板式识别等对于现今的 OCR 技术来说其实都已经不算什么问题。
但发展到现在,对于 OCR 技术来说依旧有一个瓶颈没有突破,那就是弯曲文字。
什么是弯曲文字?
像这样,

这样,

还有这样的。

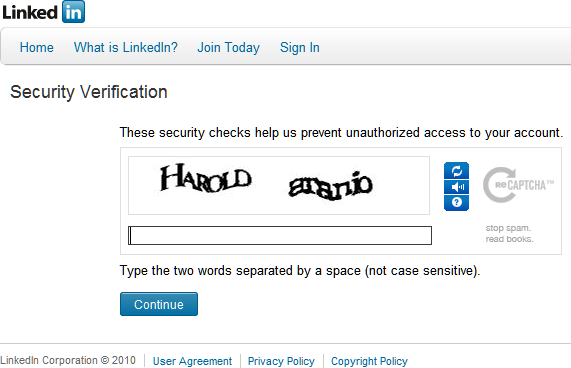
实际上,Captcha & reCAPTCHA,也就是你登录网站常常输入错的歪歪扭扭的文字验证码,也是基于 OCR 的这个弱点,来防止被攻击的。
过去的 OCR 大多是解决水平文字的检测或者倾斜文字的检测,但其实像上图的弯曲在生活中十分常见。
近日,亚马逊的研究人员就开发出了一项名为「TextTubes」来 OCR 识别算法来解决这个问题。
简单来说,该算法首先会对目标图像进行建模,建立一个曲线函数,然后再分析出出半径以及中间轴,继而生成一个文本选取分区。
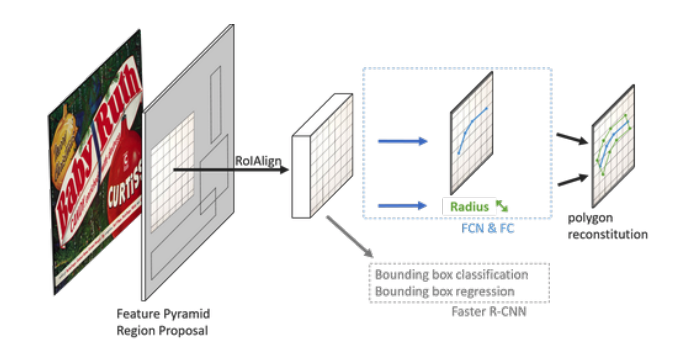
效果怎么样?
论文展示了三种不同 OCR 技术针对同一个含有弯曲字体的广告牌的识别效果。

结果显示,(b)和(c)会出现识别框重复的现象,(b)当中还出现了弯曲识别框未能完全覆盖文字的情况。
这样会带来什么结果呢,一就是会出现导出的文字结果会有重复,而二就是会导致识别结果错误。
至于 TextTubes 所识别出来的效果则很完美地对广告牌上的每一个文字区域进行分区,既不会出现重叠区域,而每一个分区也都很好地覆盖所有文字。
为了更好地测试 TextTubes 的性能,亚马逊在 CTW- 1500 以及 Total-Text 两个训练系统上进行评估。当中 CTW- 1500 含有 1500 张图像、超过 10000 个文本实体,每张图像至少还有一个弯曲文本,而 Total-Text 则共有 1255 个训练图像、300 个测试图像,每张图片也是含有一个或多个弯曲文本。

那么成绩如何?TextTubes 在两个测试中都获得了优秀的成绩,在 CTW- 1500 则更为突出,准确率为 83.65%,相比之下,排第二名的,准确率只有 75.6%。
亚马逊表示,当 TextTubes 正式投入使用之后,对于那些高度依赖 OCR 技术展开业务的企业来说,是一个福音。根据 Grand View Research 的数据,市场对于 OCR 的需求仍在不断增大,预计到 2025 年 OCR 解决方案市场规模将达到 133.8 亿美元。
等等,不是说文字验证码是基于 OCR 的这个弱点的吗?如果突破了,验证码还安全吗?
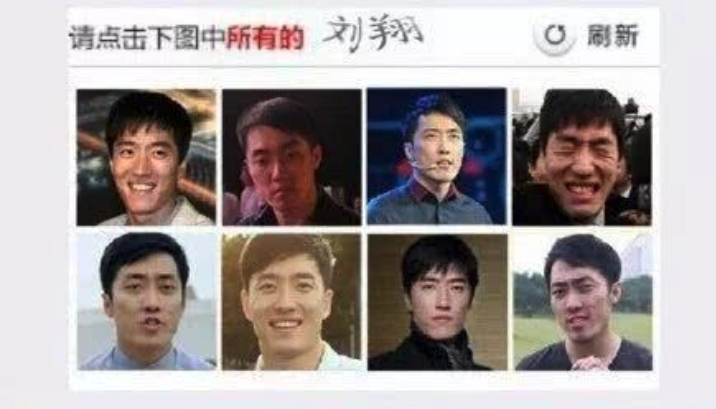
这不所以推出了从一堆刘翔中找出王自如的验证码吗?
参考资料及文中部分插图来自:《TextTubes for Detecting Curved Text in the Wild》
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
from 爱范儿 https://ift.tt/2F4ZITx
via IFTTT
没有评论:
发表评论