
「拍照优化、语音助手以外,手机 AI 还有什么?」
今年全新一代骁龙 8 移动平台发布时,高通再次翻译翻译了,什么叫脑洞大开——
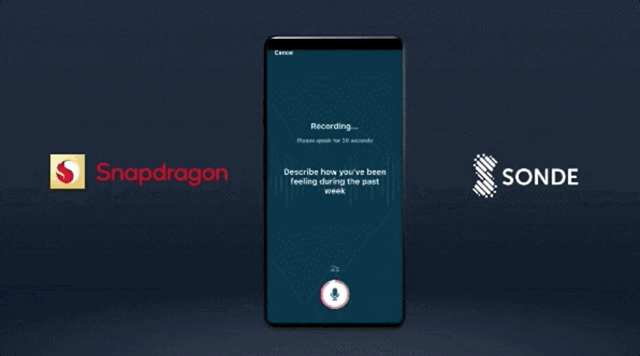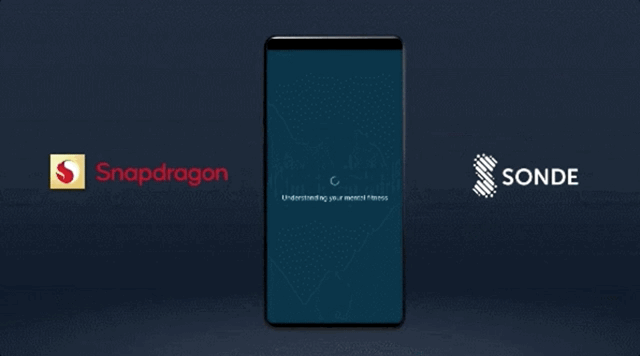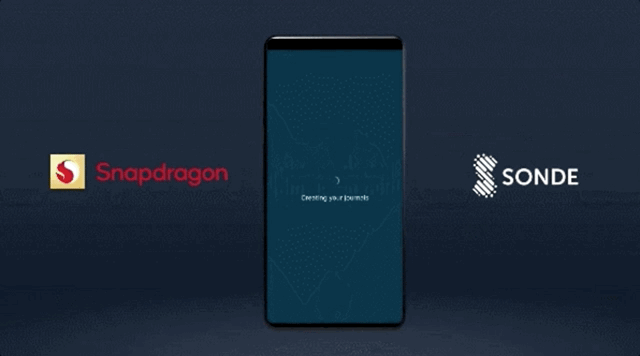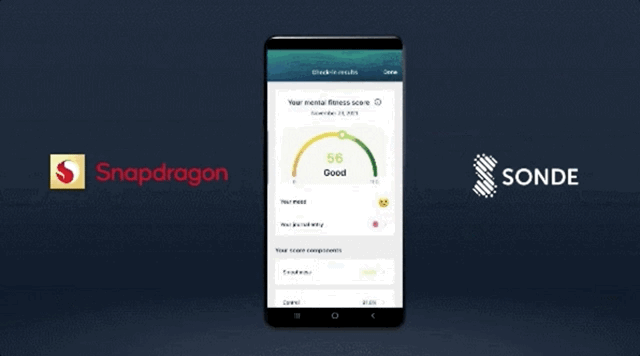
让手机学会「听诊」,通过语音识别出用户可能存在的疾病,比如抑郁症、哮喘;
让手机实现「防偷窥」,通过识别陌生用户的视线,实现自动锁屏;

让手机游戏搞定超分辨率,将以往 PC 端才有能力运行的画质,搬到手机上体验……
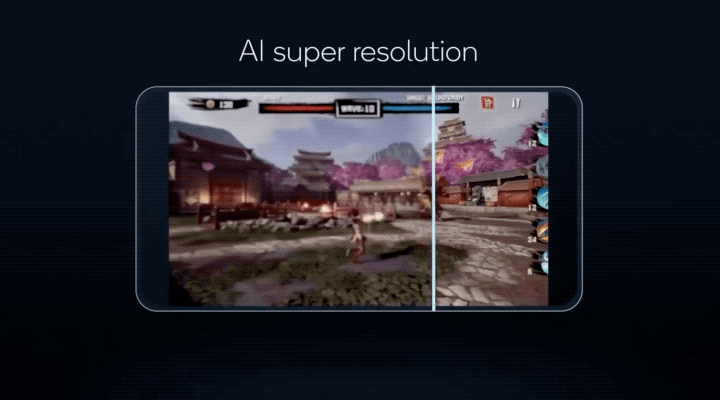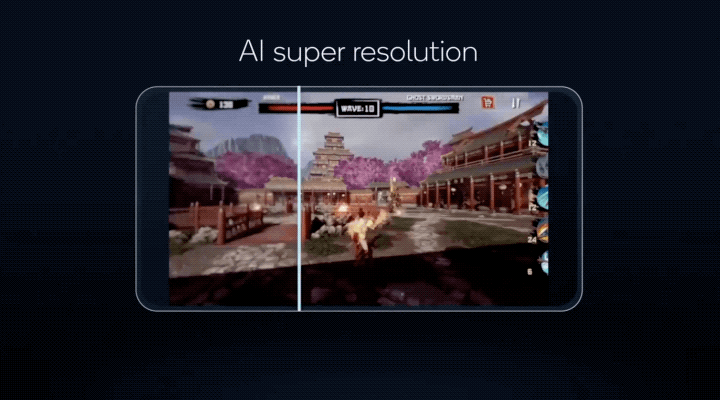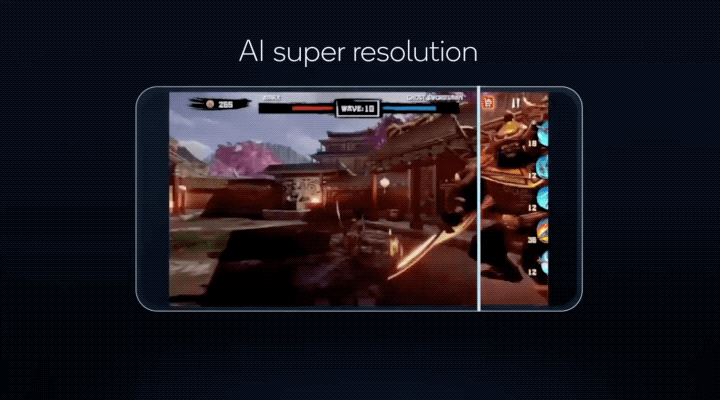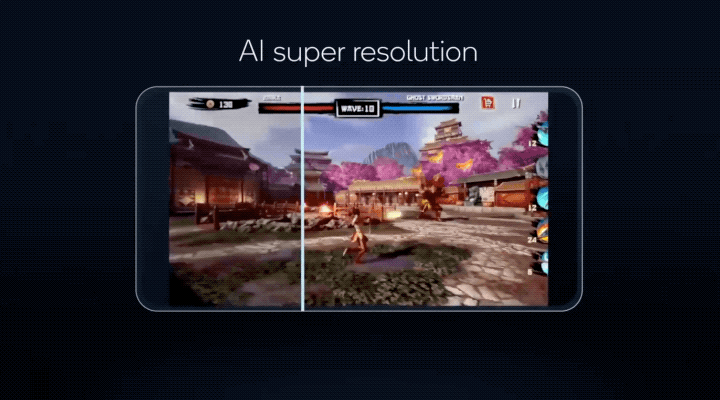
更重要的是,这些 AI 功能,骁龙 8 有能力同时运行!
高通声称,骁龙 8 搭载的第 7 代 AI 引擎,性能相比上一代最高提升了 4 倍。

这意味着我们玩手机的时候,同时「多开」几个 AI 应用也没问题。更重要的是,它不仅仅是简单的 AI 性能提升,更能给用户带来流畅的应用体验感。
在硬件制程升级如此艰难的今天,高通是如何在第 7 代 AI 引擎的性能和应用上「翻」出这么多新花样的?
我们翻了翻高通发表的一些研究论文和技术文档,从中找到了一些「蛛丝马迹」:
在高通发布的 AIMET 开源工具文档里,就有提到关于「如何压缩 AI 超分辨率模型」的信息;
在与「防偷窥」相关的一篇技术博客中,介绍了如何在隐私保护的前提下使用目标检测技术……
而这些文档、技术博客背后的顶会论文,全都来自一家机构——高通 AI 研究院。

可以说,高通把不少研究院发表的 AI 论文,「藏」在了第 7 代 AI 引擎里。
顶会论文「藏身」手机 AI
先来看看第 7 代 AI 引擎在拍照算法上的提升。
针对智能识别这个点,高通今年将面部特征识别点增加到了 300 个,能够捕捉到更为细微的表情变化。
但同时,高通又将人脸检测的速度提升了 300%。这是怎么做到的?

在一篇高通发表在 CVPR 上的研究中,我们发现了答案。
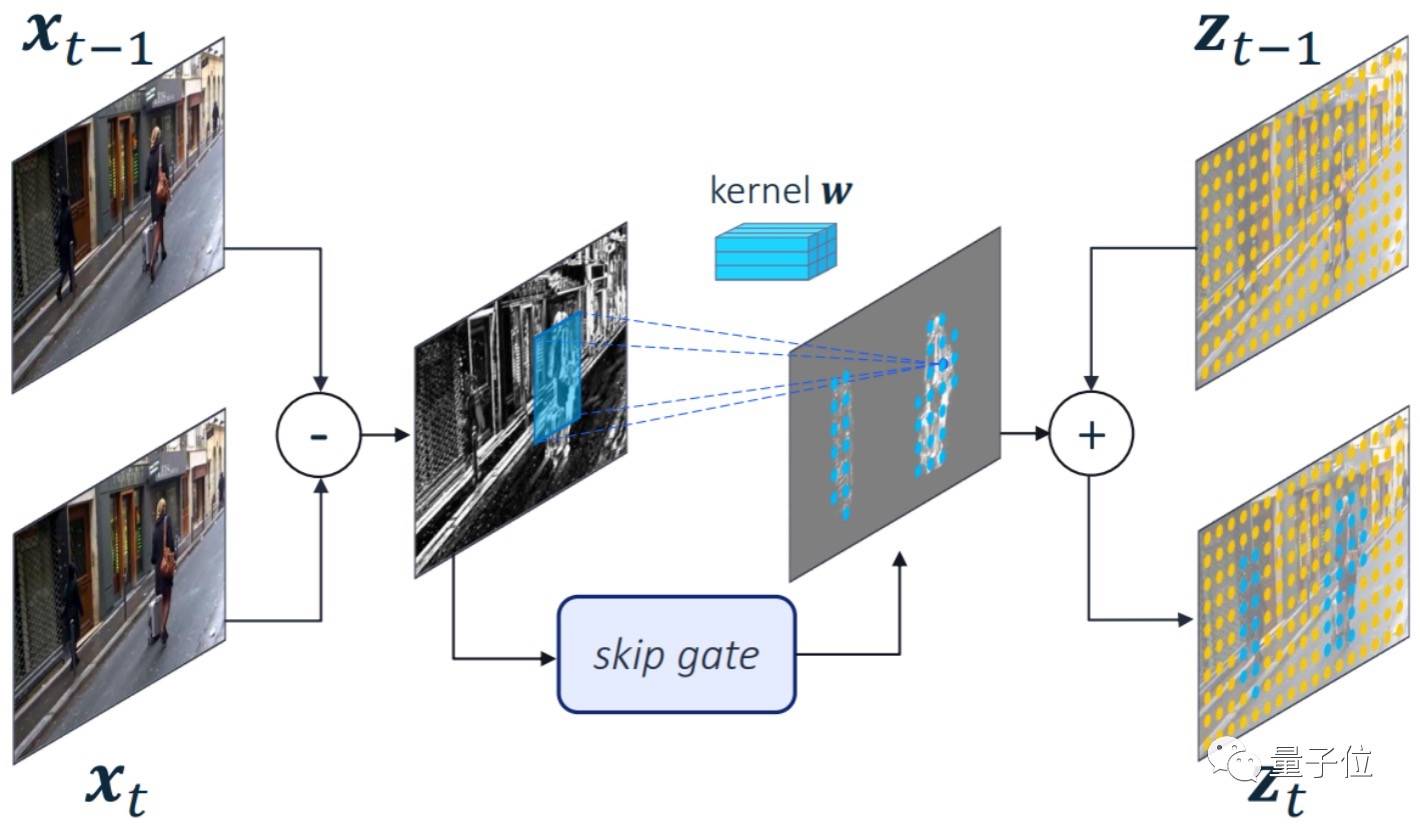
在这篇文章中,高通提出了名为 Skip-Convolutions(跳跃卷积)的新型卷积层,它能将前后两帧图像相减,并只对变化部分进行卷积。
没错,就像人的眼睛一样,更容易注意到「动起来的部分」。
这使得骁龙 8 在做目标检测、图像识别等实时检测视频流的算法时,能更专注于目标物体本身,同时将多余的算力用于提升精度。
可能你会问,这样细节的人脸识别对于拍照有什么用?
更进一步来说,这次高通与徕卡一起推出了 Leica Leitz 滤镜,用的是基于 AI 的智能引擎,其中就包括了人脸检测等算法,使得用户能更不经思考智能地拍出更具艺术风格的照片。

不止人脸检测,高通在智能拍摄上所具备的功能,还包括超分辨率、多帧降噪、局部运动补偿……
然而,在高分辨率拍摄中的视频流通常是实时的,AI 引擎究竟如何智能处理这么大体量的数据?
同样是一篇 CVPR 论文,高通提出了一个由多个级联分类器组成的神经网络,可以随着视频帧的复杂度,来改变模型所用的神经元数量,自行控制计算量。
面对智能视频处理这种「量大复杂」的流程,AI 现在也能 hold 住了。
智能拍照以外,高通的语音技术这次也是一个亮点。
像开头提到的,第 7 代 AI 引擎支持用手机加速分析用户声音模式,以确定哮喘、抑郁症等健康状况的风险。
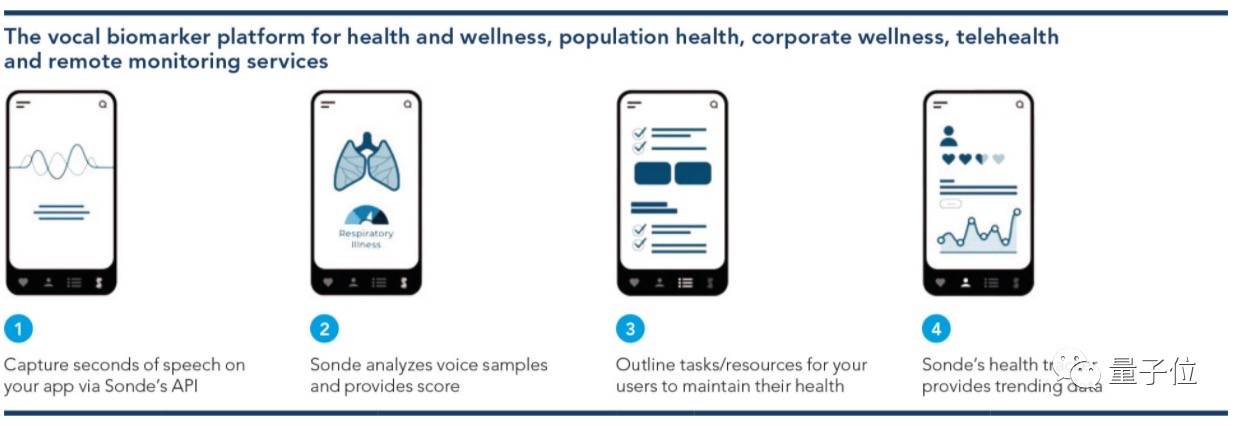
那么,它究竟是如何准确分辨出用户声音,而且又不涉及收录数据的?
具体来说,高通提出了一种手机端的联邦学习方法,既能使用手机用户语音训练模型,同时保证语音数据隐私不被泄露。
像这样的 AI 功能,有不少还能在高通 AI 研究院发表的论文中找到。
同样也能寻到蛛丝马迹的,是开头提及的 AI 提升手机性能的理论支撑。这就不得不提到一个问题:
同时运行这么多 AI 模型,高通究竟是怎么提升硬件的处理性能的?
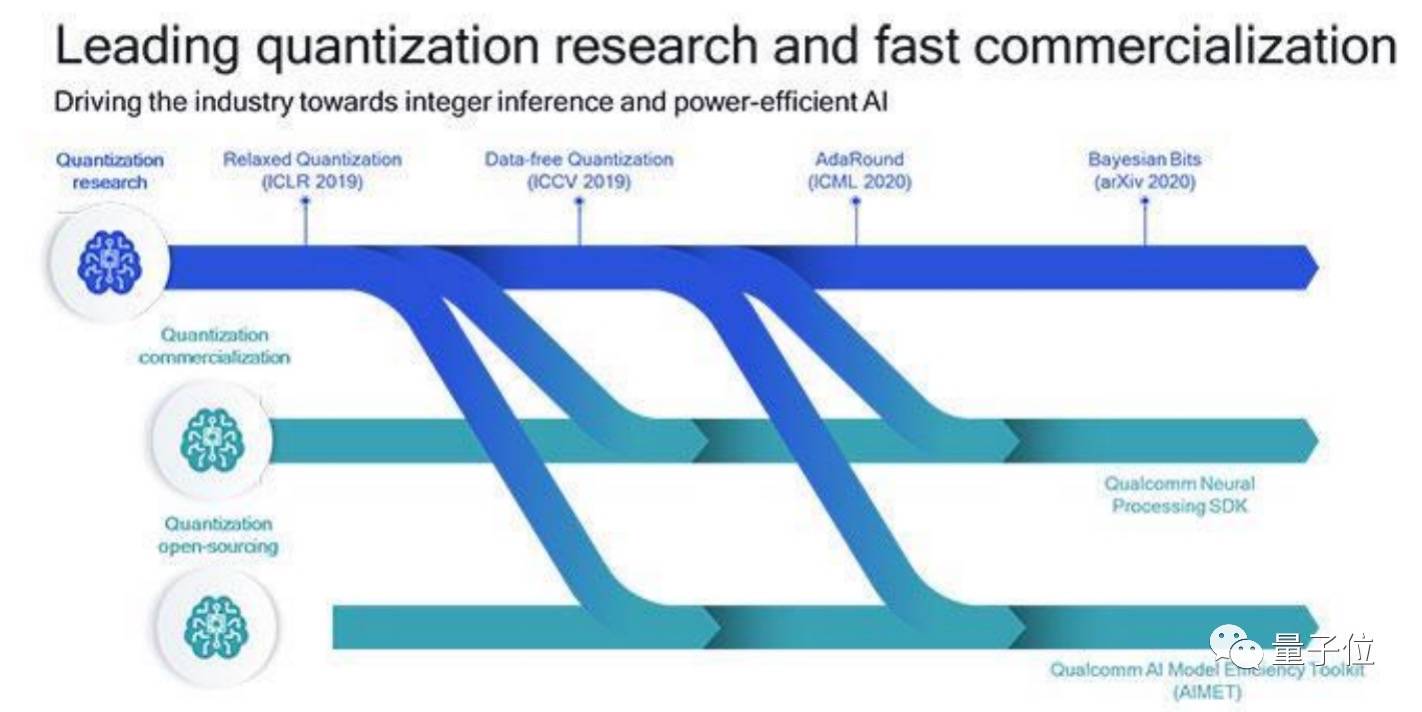
这里就不得不提到高通近几年的一个重点研究方向量化了。
从高通最新公布的技术路线图来看,模型量化一直是 AI 研究院这几年钻研的核心技术之一,目的就是给 AI 模型做个「瘦身」。
由于电量、算力、内存和散热能力受限,手机使用的 AI 模型和 PC 上的 AI 模型有很大不同。
在 PC 上,GPU 动辄上百瓦功率,AI 模型的计算可以使用 16 或 32 位浮点数(FP16、FP32)。而手机 SoC 只有几瓦功率,也难存储大体积 AI 模型。
这时候就需要将 FP32 模型缩小成 8 位整数(INT8)乃至 4 位整数(INT4),同时确保模型精度不能有太大损失。

以 AI 抠图模型为例,我们以电脑处理器的算力,通常能实现十分精准的 AI 抠图,但相比之下,如果要用手机实现「差不多效果」的 AI 抠图,就得用到模型量化的方法。
为了让更多 AI 模型搭载到手机上,高通做了不少量化研究,发表在顶会上的论文就包括免数据量化 DFQ、四舍五入机制 AdaRound,以及联合量化和修剪技术贝叶斯位(Bayesian Bits)等。
其中,DFQ 是一种无数据量化技术,可以减少训练 AI 任务的时间,提高量化精度性能,在手机上最常见的视觉 AI 模型 MobileNet 上,DFQ 达到了超越其他所有方法的最佳性能:
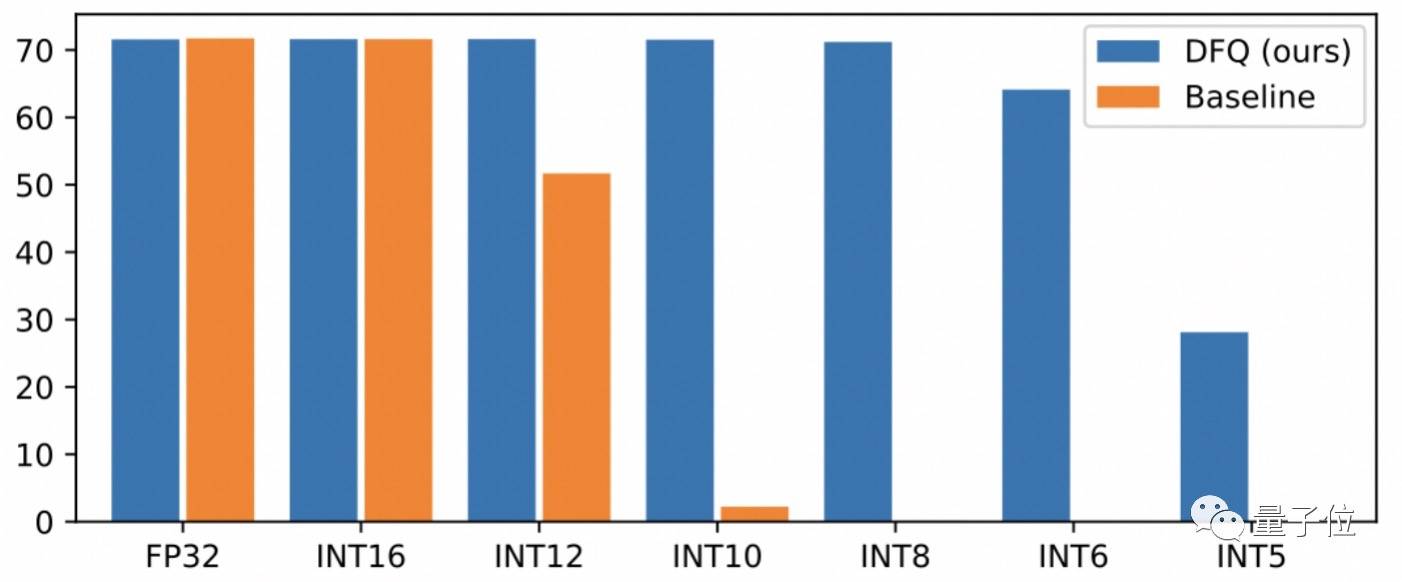
AdaRound 则可以将复杂的 Resnet1 8 和 Resnet 50 网络的权重量化为 4 位,大大减少了模型的存储空间,同时只损失不到 1% 的准确度:
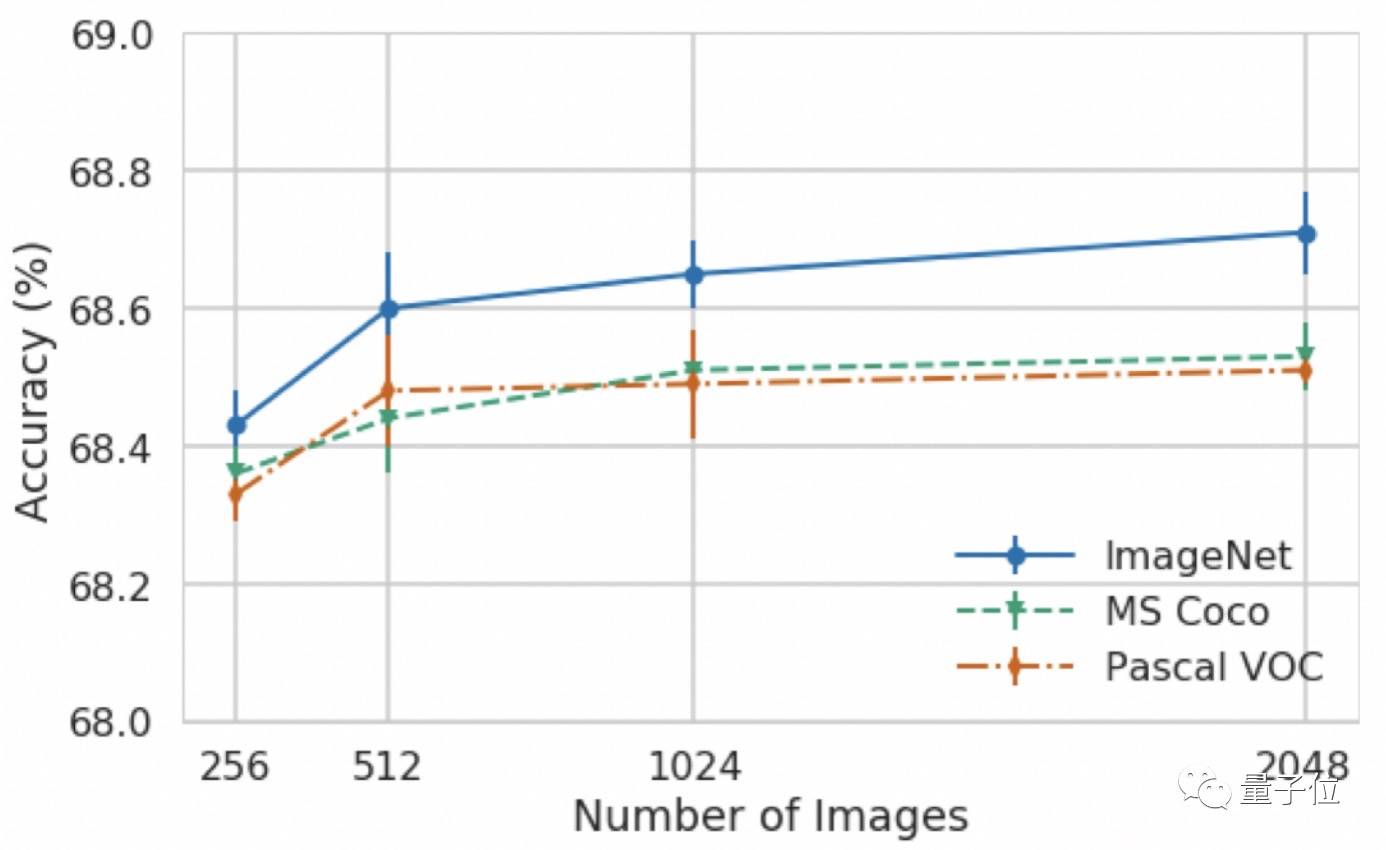
贝叶斯位作为一种新的量化操作,不仅可以将位宽度翻倍,还能在每个新位宽度上量化全精度值和之前四舍五入值之间的残余误差,做到在准确性和效率之间提供更好的权衡。
这些技术不仅让更多 AI 模型能以更低的功耗在手机上运行,像原本只能在电脑上运行的游戏 AI 超分辨率(类似 DLSS),现在实现能在骁龙 8 上运行的效果;
甚至其中一些 AI 模型,还能「同时运行」,例如其中的姿态检测和人脸识别:

事实上,论文还只是其中的第一步。
要想快速将 AI 能力落地到更多应用上,同样还需要对应的更多平台和开源工具。
将更多 AI 能力释放到应用上
对此,高通保持一个开放的心态。
这些论文中高效搭建 AI 应用的方法和模型,高通 AI 研究院通过合作、开源等方法,将它们分享给了更多开发者社区和合作伙伴,我们也因此能在骁龙 8 上体验到更多有意思的功能和应用。
一方面,高通与谷歌合作,将快速开发更多 AI 应用的能力分享给了开发者。
高通在骁龙 8 上搭载了谷歌的 Vertex AI NAS 服务,还是每月更新的那种,意味着开发者在第 7 代 AI 引擎上开发的 AI 应用,其模型性能也能快速更新。
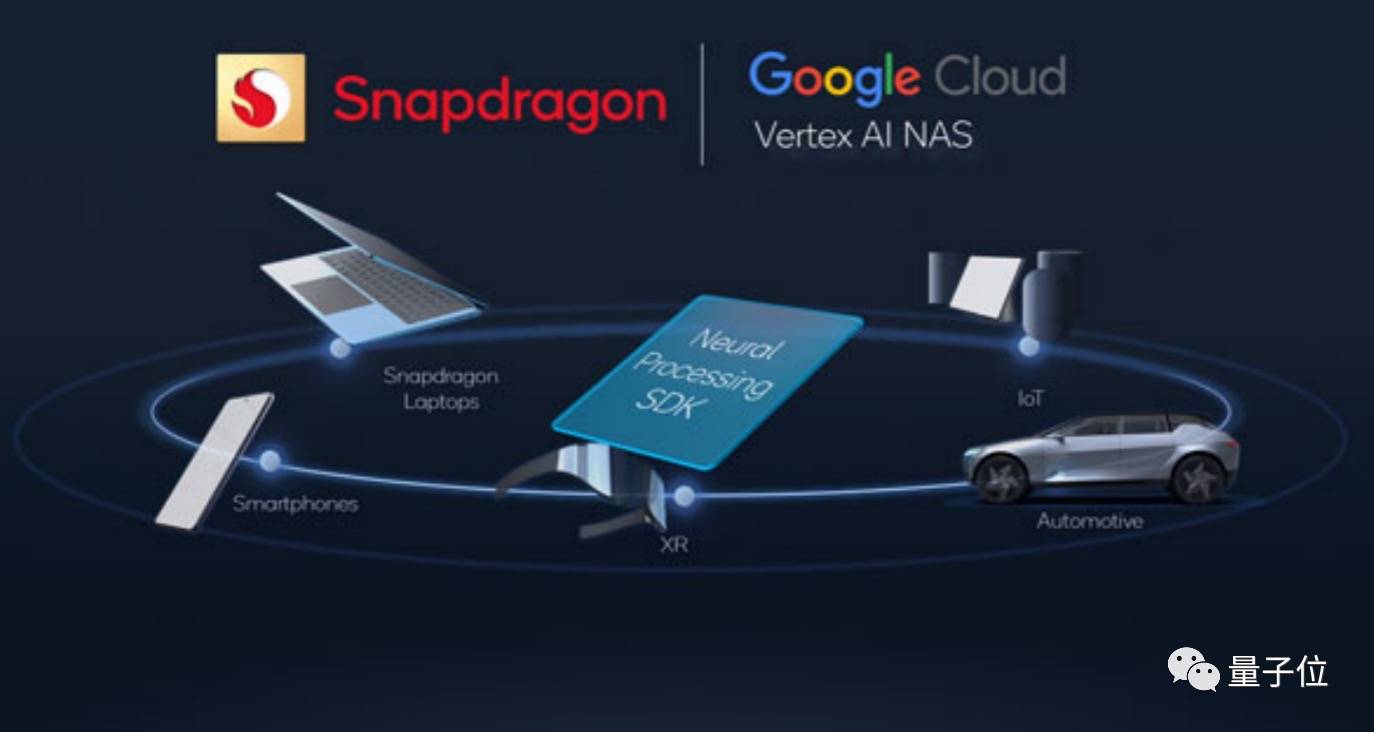
采用 NAS,开发者就能自动用 AI 生成合适的模型,包括高通发表在顶会上的智能拍照算法、语音翻译、超分辨率……都能包含在 AI 的「筛选范围」中,自动为开发者匹配最好的模型。
这里用上了高通的运动补偿和插帧等算法。而类似于这些的 AI 技术,开发者们也都能通过 NAS 实现,还能让它更好地适配骁龙 8,不会出现「调教不力」的问题。
想象一下,你将来用搭载骁龙 8 的手机打游戏时,会感觉画面更流畅了,但是并不会因此掉更多的电(指增加功耗):

同时,关于 AI 模型的维护也变得更简单。据谷歌表示,与其他平台相比,Vertex AI NAS 训练模型所需的代码行数能减少近 80%。
另一方面,高通也已经将自己这些年研究量化积累的工具进行了开源。
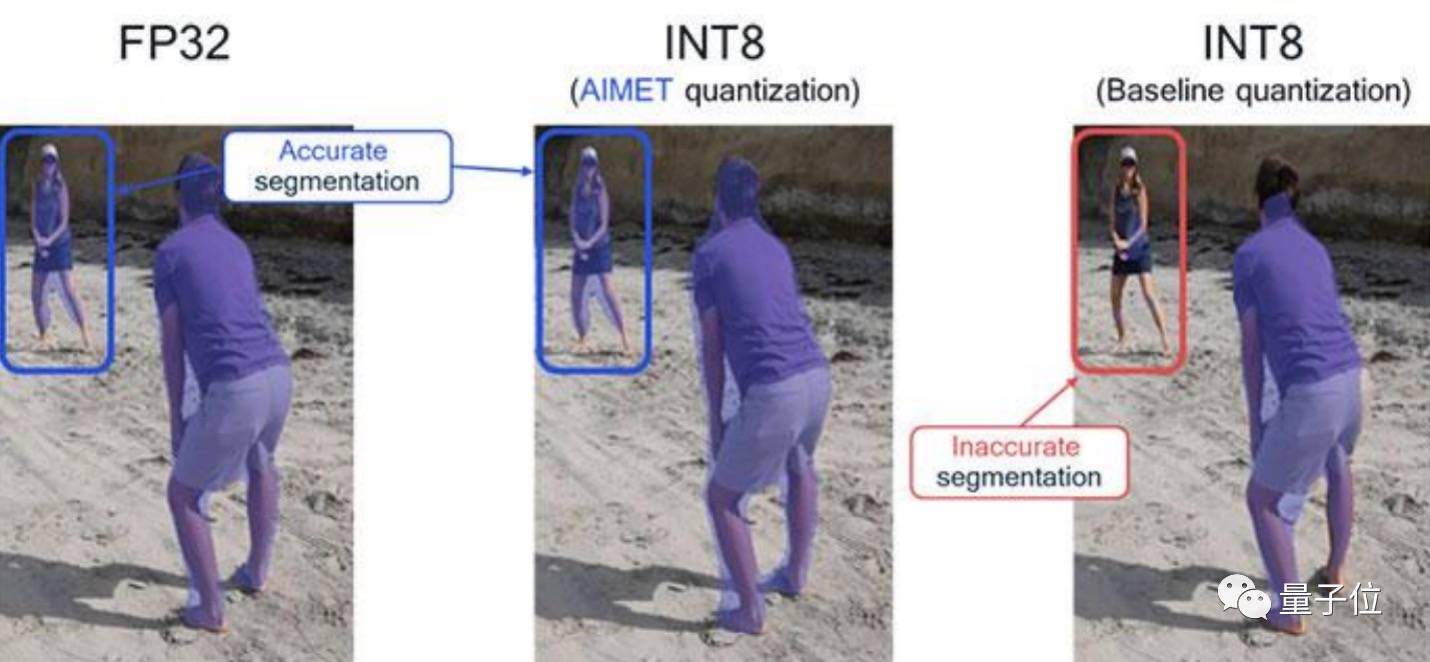
去年,高通就开源了一个名为 AIMET(AI Model Efficiency Toolkit)的模型「提效」工具。
其中包含如神经网络剪枝、奇异值分解(SVD)等大量压缩和量化算法,有不少都是高通 AI 研究院发表的顶会论文成果。开发者用上 AIMET 工具后,就能直接用这些算法来提效自己的 AI 模型,让它更流畅地在手机上运行。

高通的量化能力也不止开源给普通开发者,同样能让头部 AI 企业的更多 AI 应用在骁龙 8 上实现。
在新骁龙 8 上,他们与 NLP 领域知名公司 Hugging Face 进行合作,让手机上的智能助手可以帮用户分析通知并推荐哪些可优先处理,让用户对最重要的通知一目了然。
在高通 AI 引擎上运行它们的情绪分析模型时,能做到比普通 CPU 速度快 30 倍。

正是技术研究的沉淀和技术上保持的开放态度,才有了高通不断刷新手机业界的各种 AI「新脑洞」:
从之前的视频智能「消除」、智能会议静音,到今年的防窥屏、手机超分辨率……
还有更多的论文、平台和开源工具实现的 AI 应用,也都被搭载在这次的 AI 引擎中。
而一直隐藏在这些研究背后的高通 AI 研究院,也随着第 7 代 AI 引擎的亮相而再次浮出水面。
高通 AI 的「软硬兼备」
大多数时候,我们对于高通 AI 的印象,似乎还停留在 AI 引擎的「硬件性能」上。
毕竟从 2007 年启动首个 AI 项目以来,高通一直在硬件性能上针对 AI 模型提升处理能力。
然而,高通在 AI 算法上的研究,同样也「早有筹谋」。
2018 年,高通成立 AI 研究院,负责人是在 AI 领域久负盛名的理论学者 Max Welling,而他正是深度学习之父 Hinton 的学生。
据不完全统计,高通自成立 AI 研究院以来,已有数十篇论文发表在 NeurIPS、ICLR、CVPR 等 AI 顶级学术会议上。

其中,至少有 4 篇模型压缩论文已在手机 AI 端落地实现,还有许多计算机视觉、语音识别、隐私计算相关论文。
上述的第 7 代 AI 引擎,可以说只是高通近几年在 AI 算法研究成果上的一个缩影。
通过高通 AI 的研究成果,高通还成功将 AI 模型拓展到了诸多最前沿技术应用的场景上。
在自动驾驶上,高通推出了骁龙汽车数字平台,「包揽」了从芯片到 AI 算法的一条龙解决方案,目前已同 25 家以上的车企达成合作,使用他们方案的网联汽车数量已经达到 2 亿辆。
其中,宝马的下一代辅助驾驶系统和自动驾驶系统,就将采用高通的自动驾驶方案。
在 XR 上,高通发布 Snapdragon Spaces XR 了开发平台,用于开发头戴式 AR 眼镜等设备和应用。
通过和 Wanna Kicks 合作,骁龙 8 还将第 7 代 AI 引擎的能力带到了 AR 试穿 APP 上。

在无人机上,高通今年发布了 Flight RB5 5G 平台,其中有不少如 360° 避障、无人机摄影防抖等功能,都能通过平台搭载的 AI 模型实现。其中首架抵达火星的无人机「机智号」,搭载的就是高通提供的处理器和相关技术。
回过头看,不难发现这次高通在 AI 性能上不再强调硬件算力(TOPS)的提升,而是将软硬件作为一体,得出 AI 性能 4 倍提升的数据,并进一步强化 AI 应用体验的全方位落地。
这不仅表明高通更加注重用户实际体验的感受,也表明了高通对自身软件实力的信心,因为硬件已经不完全是高通 AI 能力的体现。
可以说骁龙 8 第 7 代 AI 引擎的升级,标志着高通 AI 软硬一体的开端。
最近,高通针对编解码器又提出了几篇最新的研究,分别登上了 ICCV 2021 和 ICLR 2021 。
这些论文中,高通同样用 AI 算法,展现了针对编解码器优化的新思路。
在一篇采用 GAN 原理的研究中,高通最新的编解码器算法让图像画面不仅更清晰、每帧也更小了,只需要 14.5KB 就能搞定:

相比之下,原本的编解码算法每帧压缩到 16.4KB 后,树林就会变得无比模糊:

而在另一篇用插帧的思路结合神经编解码器的论文中,高通选择将基于神经网络的 P 帧压缩和插帧补偿结合起来,利用 AI 预测插帧后需要进行的运动补偿。
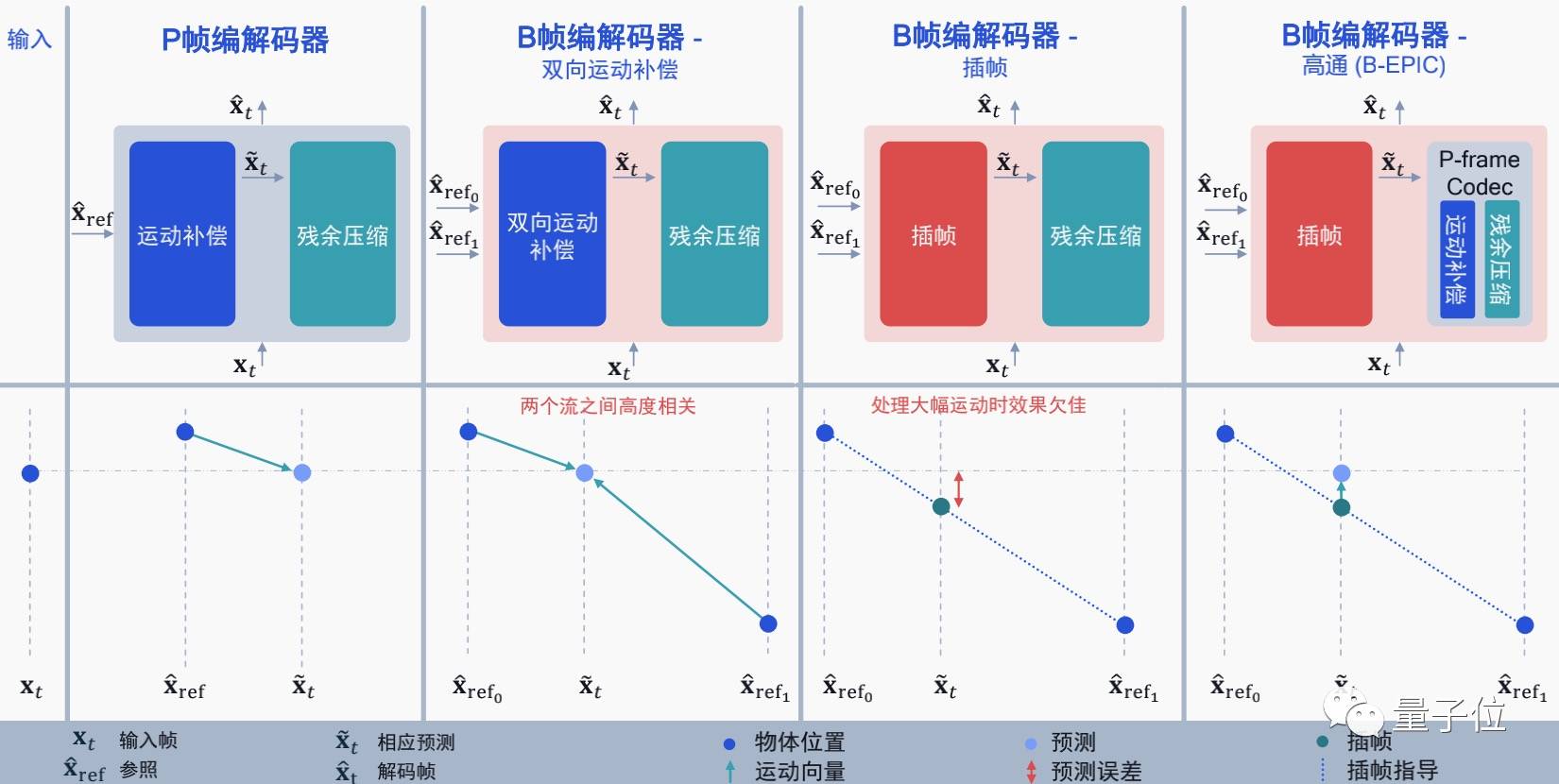
经过测试,这种算法比谷歌之前在 CVPR 2020 上保持的 SOTA 纪录更好,也要好于当前基于 H.265 标准实现开源编解码器的压缩性能。
将 AI 模型应用于更多领域中,高通已经不是第一次尝试,像视频编解码器的应用,就又是一个新的方向。
如果这些模型能成功被落地到平台甚至应用上,我们在设备上看视频的时候,也能真正做到不卡。
随着「软硬一体」的方案被继续进行下去,未来我们说不定真能看见这些最新的 AI 成果被应用到智能手机上。
结合高通在 PC、汽车、XR 等领域的「秀肌肉」……
可以预见的是,你熟悉的高通、你熟悉的骁龙,肯定不会止于手机,其 AI 能力,也将不止于手机。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
from 爱范儿 https://ift.tt/30SUvNc
via IFTTT
没有评论:
发表评论