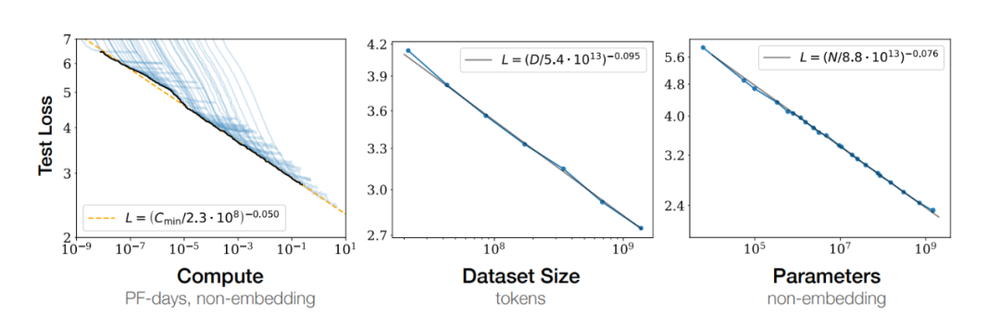
微软上季度云服务收入增长强劲,Surface 业绩连续七季度下滑

雷军谈理想 MEGA:很多公司目标定得过大,不认为自己是从零到一

特斯拉撞人事故发生时处于 FSD 模式

消息称拼多多将 GMV 放回第一目标

比亚迪与 Uber 达成合作

云计算和 AI 热潮推动,三星二季度营收利润高于预期

AI 搜索引擎 Perplexity 将与出版商达成协议,此前被指控违规抓取内容

英伟达黄仁勋:每个人都将拥有 AI 助手

全新华为 MatePad Pro/Air 平板将于 8 月 6 日发布

iPhone 16 再曝光新背板配色图
英特尔官宣 Lunar Lake 处理器 9 月 3 日发布

XREAL Air 2 Ultra 智能 AR 眼镜国行发售
苹果新专利探索「心跳」解锁 iPhone

Adobe Illustrator 推出原生 Windows on ARM 应用

网络主播正式成为国家新职业

星巴克中国上财季三大指标环比增长

瑞幸咖啡单季营收创新高

微软上季度云服务收入增长强劲,Surface 业绩连续七季度下滑
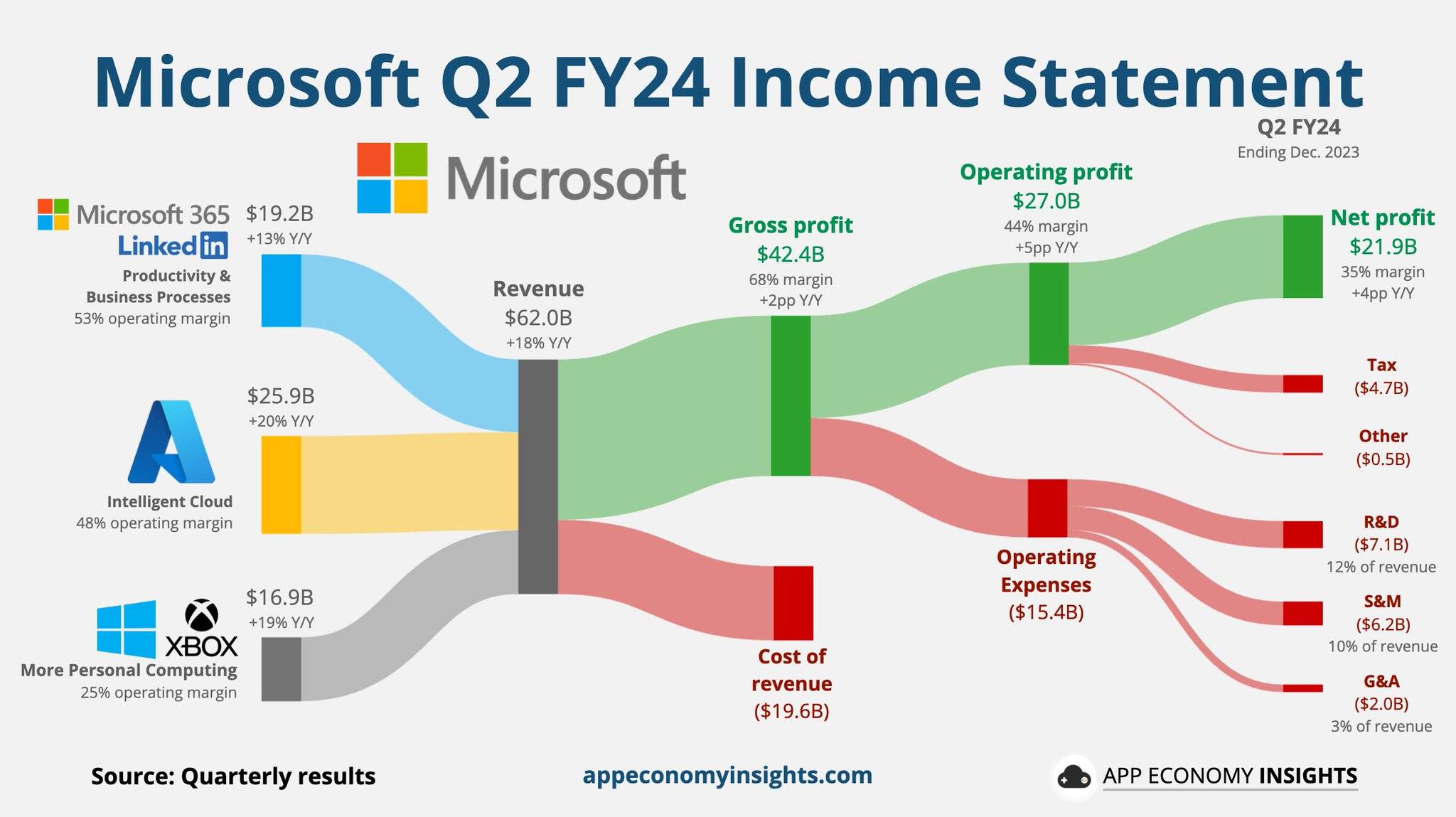
昨日,微软公司发布了 2024 年第四财季(今年第二季度,截至 6 月 30 日)的业绩报告。第四财度,微软收入约 647 亿美元,同比增长 15%;净利润约为 220 亿美元,同比增长了 10%。
具体业务来看,微软的智能云收入(服务器产品和云服务)总体约为 285 亿美元,同比增长 19%,占总收入近 45%;生产力和业务流程收入约 203 亿美元,增长 11%。
消费设备业务方面,Xbox 硬件收入再次下滑,而 Surface 收入已经连续七个季度下滑。不过,微软已经在第四财季末推出了新款的 Surface Pro 和 Surface Laptop 设备,其对设备收入的全面影响要等下个季度才会完全显现。
微软也公布了截至 2024 年 6 月 30 日的 2024 财年业绩,总收入约为 2451 亿美元,增长 16%;净利润约为 881 亿美元,增长 22%。
微软 CEO Satya Nadella 表示,微软作为一家平台公司,专注于通过目前的大规模平台满足客户的关键任务需求,同时确保微软引领人工智能时代的到来。
有报道称,由于业绩表现亮眼,微软已向员工宣布,将额外给予全体员工一笔现金奖励,表彰其优秀的表现。

雷军谈理想 MEGA:很多公司目标定得过大,不认为自己是从零到一

昨日,作家李翔放出今年 4 月与小米 CEO 雷军将近 4 小时的采访内容,谈到了小米造车的故事和雷军对于行业的一些看法。
在谈到世界上最顶级的公司跨越新业务为什么会失败时,雷军表示,很多公司目标定得过大,不认为自己是「从零到一」做起。雷军举例了理想汽车首款纯电 MPV 车型 MEGA。他认为,理想 CEO 李想做增程汽车取得成绩,在做纯电时认为顺手就做了,但其实他做纯电也是从零到一。
当被问到希望自己的 IP 是一个什么形象时,雷军表示被称为「营销之神」不是自己本意,这也低估了小米在研发和产品上的付出,小米的目标是成为全球新一代的技术引领者。
雷军也表示,他们正在认真学习理想、华为是怎么做营销的,在这些方面,他们比小米做得「好很多」。
特斯拉撞人事故发生时处于 FSD 模式

美国华盛顿州当局已经确认,今年 4 月在西雅图发生的特斯拉汽车与摩托车手相撞事故发生时,特斯拉汽车正在运行 FSD(Full Self- Driving,完全自动驾驶)模式。事故造成了摩托车手死亡。
肇事司机目前已被逮捕,华盛顿州高速公路巡警队发言人表示,肇事司机承认自己在 FSD 模式下驾驶注意力不集中,并且在向前行驶时分心使用手机,相信机器会为他驾驶。目前还未对司机发出任何指控。
特斯拉 CEO 埃隆·马斯克在上个月预告,在解决了 FSD 的已知问题后,用户在一年内或许都遇不到一次需要接管车辆的情况。
消息称拼多多将 GMV 放回第一目标

晚点独家报道,拼多多在今年第二季度调整了业务重点,从追求商业化、提升利润,转向将 GMV(商品交易总额)放回第一目标。
据报道,不只有拼多多一家把 GMV 放在首位。抖音电商近期调整经营目标优先度,GMV 增长取代价格力成为下半年重点;淘天在 618 后淡化价格力战略,不再对标拼多多,GMV 成为最重要的指标。
报道还称,拼多多正在考虑将旗下跨境电商平台 Temu 的经验用在国内业务,在部分品类上尝试「全托管」模式,即商家负责供货,平台决定零售价,实现更低价。
拼多多核心管理层也在内部强调,国内业务仍然需要进一步提高人效。
比亚迪与 Uber 达成合作

比亚迪和出行平台公司 Uber 昨天宣布建立多年战略合作伙伴关系,旨在将 10 万辆比亚迪电动汽车引入 Uber 全球的平台。
据介绍,该合作伙伴关系将从欧洲和拉丁美洲开始,并扩大到中东、加拿大、澳大利亚、新西兰等市场。
两家公司的合作还可能包括为司机提供充电、车辆保养、保险折扣,以及融资和租赁优惠等等。
双方还将合作开发未来的比亚迪自动驾驶汽车,并将其部署在 Uber 平台上。
云计算和 AI 热潮推动,三星二季度营收利润高于预期

昨天,三星电子公开了今年第二季度的业绩报告。财报显示,三星二季度综合收入为 74.07 万亿韩元(折合人民币约为 3900 亿元),净利润为 10.44 万亿韩元(折合人民币约为 550 亿元)。
此前,伦敦证券交易所集团分析师预估三星二季度收入在 73.84 万亿韩元、净利润在 9.53 万亿韩元左右,因此三星二季度表现超越了市场预估。
具体业务中,负责半导体业务的 DS(Device Solution)部门以 28.56 万亿韩元的收入和 6.45 万亿韩元的利润成为整体业绩大头。三星表示,云计算服务和人工智能的热潮导致了像 HBM(高带宽内存)和 DDR5 内存需求激增,销售扩大。HBM 的销售额环比增长了 50%
三星预计,在 AI 应用不断扩大的趋势下,今年下半年市场对 HBM、DDR5 和服务器 SSD 的需求将保持强劲,因此将扩大产能增加 HBM3E 销售比例。
财报中,三星也首次确认了新一代移动处理器 Exynos 2500 芯片的存在,这款芯片将采用 3nm 工艺,Galaxy S25 系列手机将搭载。
AI 搜索引擎 Perplexity 将与出版商达成协议,此前被指控违规抓取内容

AI 搜索引擎 Perplexity 启动了一项与出版合作伙伴分享广告收入的计划,此前,有出版商指控 Perplexity 会抄袭一些不允许 AI 抓取的内容。
目前,Perplexity 的「出版商计划」已经和第一批合作伙伴达成协议,包括《时代周刊》《明镜周刊》《财富》《企业家》等知名出版商。
根据协议,当 Perplexity 响应用户查询提供这些出版商的内容时,出版商也将获得广告收入的一部分。这些合作伙伴还将获得 Perplexity 企业专业版的一年免费订阅,并能访问 Perplexity 开发者工具。Perplexity 还会通过第三方公司提供出版商内容出现在搜索结果中的频率等等数据。
Perplexity 拒绝透露具体的交易细节,表示收入分成是多年协议,分成有「两位数的百分比」。Perplexity 计划于 9 月份引入广告。
英伟达黄仁勋:每个人都将拥有 AI 助手

英伟达 CEO 黄仁勋和《连线》杂志编辑 Lauren Goode 在 SIGGRAPH 大会上讨论了 AI 如何增强未来人类生产力等话题。
黄仁勋认为,未来每个人都会有一个 AI 助手,每一家公司、公司内的每一项工作都将得到 AI 的帮助。
黄仁勋也表示,生成式 AI 能提升人类生产力,支撑其的加速计算技术则有望使计算更加节能,加速计算可以节省 20 倍甚至 50 倍的能耗,并能完成同样的处理工作。黄仁勋认为,应加速每一个应用,进而减少全世界能源使用量。
这次谈话之前,英伟达推出了一套新的 NIM 推理微服务,专为各种工作流程量身定制,包括 OpenUSD、3D 建模、物理、材料、机器人、工业数字孪生和物理 AI。

全新华为 MatePad Pro/Air 平板将于 8 月 6 日发布

华为昨日官宣,全新华为 MatePad Pro、华为 MatePad Air 将于 8 月 6 日 14:30 的发布会上推出。
根据预热文案,两款平板将搭载华为联合中国美术学院开发的「天生绘画」绘图 App,也将会带来更多 AI 相关功能。
两款平板将在华为鸿蒙智行享界 S9 及华为全场景新品发布会上推出,发布会还将会带来 nova 首款小折叠手机 nova Flip 等更多新品。
iPhone 16 再曝光新背板配色图

爆料博主 Sonny Dickson 在 X 平台上发布了一张 iPhone 16 机模图片,展示了新 iPhone 手机的背板和配色。
新的爆料图和此前的其他图片类似,都显示 iPhone 16 的摄像头布局将垂直排列,类似 iPhone X,有消息称这将使 iPhone 16 和 iPhone 16 Plus 支持录制空间视频。
新的爆料图还展示了 iPhone 16 的新配色,总体上比 iPhone 15 更深。该名博主去年爆料的 iPhone 15 机模配色与实机相似度较高。
英特尔官宣 Lunar Lake 处理器 9 月 3 日发布

英特尔发布公告,官宣将在德国柏林于当地时间 9 月 3 日(北京时间 9 月 4 日)发布代号为「Lunar Lake」的全新一代英特尔酷睿 Ultra 处理器。
发布会上,英特尔将详细介绍 Lunar Lake 处理器在 x86 能效、核心性能、图形性能和 AI 计算能力上的突破。
在今年的台北电脑展上,英特尔已经介绍了 Lunar Lake 的部分细节。Lunar Lake 处理器号称在 SoC 功耗上降低多达 40%,NPU 可提供至高 48 TOPS AI 算力,并直接将内存芯片集成于处理器的封装中。
XREAL Air 2 Ultra 智能 AR 眼镜国行发售

XREAL Air 2 Ultra 智能 AR 眼镜昨日正式宣布发售,售价 3999 元。
据介绍,XREAL Air 2 Ultra 搭载了自研手势交互算法和自研 SLAM 算法,支持完整的 6 自由度空间悬停,视场角为 52 度。眼镜单眼分辨率为 1080p,支持 500 尼特亮度,刷新率可达 120Hz。眼镜还支持 iPhone 15 Pro 的空间视频格式。
苹果新专利探索「心跳」解锁 iPhone
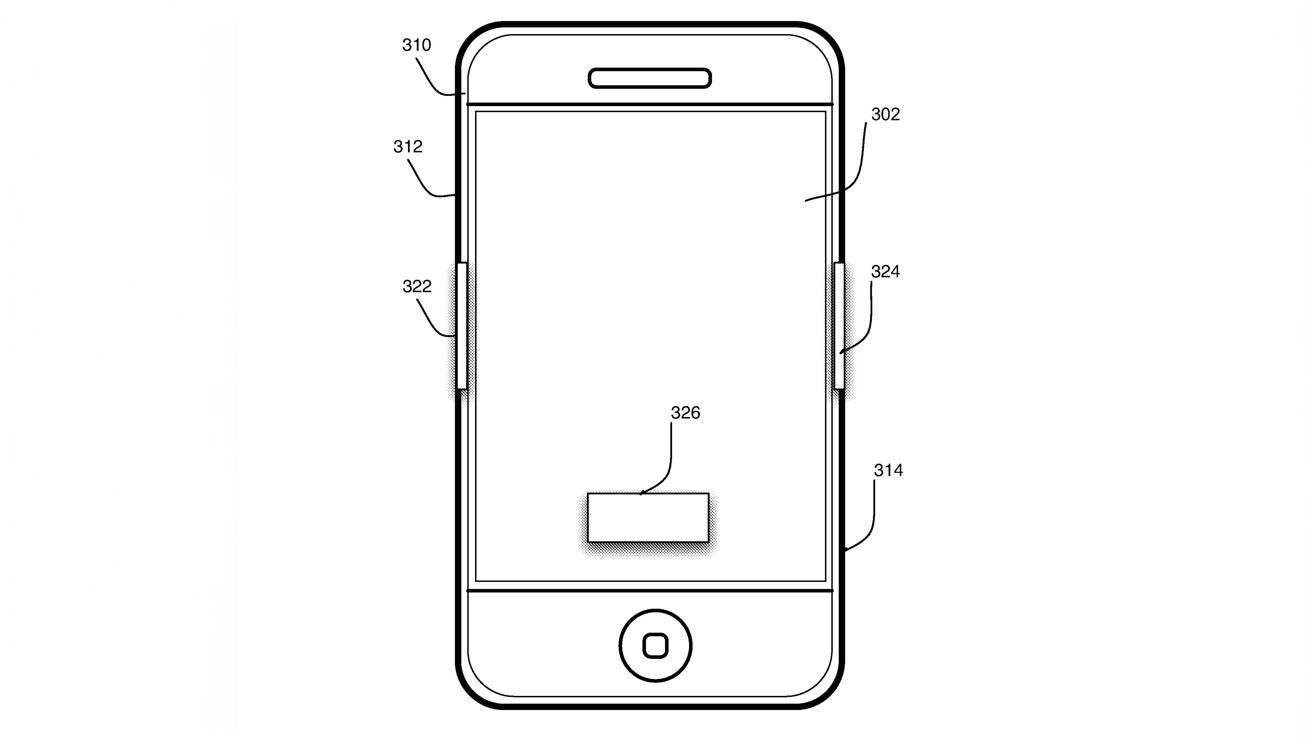
在一项新的专利中,苹果公司讨论了一种根据每个用户独特的心血管测量结果,来识别用户的技术。
借助这项技术,Apple Watch 可以识别用户心电图来进行解锁,并以此来解锁其他苹果设备。
苹果的专利中还描述了一种新的 iPhone 设计:只需要正确握住 iPhone,就可以用心率进行身份认证,iPhone 的外表变成一个心脏测量设备。
除了「Heart ID」,苹果还讨论了如何使用心电图数据感知用户的「情绪」,例如,在锻炼期间测量心脏特征,并推送有着相匹配 BPM 的音乐。
Adobe Illustrator 推出原生 Windows on ARM 应用

Adobe 公司为 Windows on ARM 系统推出了基于 ARM 架构原生开发的 Adobe Illustrator 测试版。在这之前,Photoshop 和 Lightroom 都已经推出了 ARM 原生版本应用。
在今年的微软发布会上,Adobe 承诺将为 Creative Cloud 套件全面适配 Windows on ARM 平台。Adobe 曾表示将在 7 月推出 Illustrator 和 InDesign 的 ARM 版本,但目前后者仍未到来。

网络主播正式成为国家新职业

昨日,人社部会同国家市场监督管理总局、国家统计局正式增设网络主播为国家新职业,这标志着网络主播的职业身份在「国家确定职业分类」上首次得以确立。
人社部此前印发的一个通知指出,新职业从业者可以享受国家职业技能培训补贴和职业技能鉴定补贴等有关政策待遇,以及高技能人才与专业技术人才职业发展相关政策。
星巴克中国上财季三大指标环比增长

星巴克发布第三财季财报,财报显示截至 6 月 30 日的第三财季,星巴克净收入 91 亿美元。
至于中国市场,全季度收入 7.338 亿美元,较上一季度增长 5%。
同样环比增长的还有门店交易量,和整体经营利润率。前者实现逐月增长,季度环比攀升;后者连续两个季度环比增长,始终保持双位数的利润率。
第三财季,星巴克在中国新增门店 213 家,星巴克预计,按照目前的开店节奏,本财年新开门店数将突破纪录。
星巴克 CEO 纳思瀚表示,将围绕卓越的伙伴体验、对独一无二和高质量咖啡体验的坚持、门店服务本地社区三项原则和高端定位,建立星巴克中国业务。
瑞幸咖啡单季营收创新高

瑞幸咖啡发布第二季度财报,全季度实现收入 84 亿元,同比增长 35.5%,创下单季营收新高,净利润为 8.7 亿元。
其中,自营门店实现收入 62.8 亿元,同比增长 39.6%;联营门店单季度收入 18.5 亿元,同比增长 24.5%。
今年上半年,瑞幸咖啡总净收入达到 146.8 亿人民币,同比增长 38%。
瑞幸咖啡 CEO 郭谨一表示,虽然行业竞争依旧激烈,但瑞幸咖啡凭借先进的商业模式、产品创新以及规模优势,成功实现业绩改善。

《爱情到此为止》内地定档 8 月 30 日

由布蕾克·莱弗利主演的爱情电影《爱情,到此为止》中国内地正式定档 8 月 30 日上映,北美将于 8 月 9 日上映。
电影由贾斯汀·贝尔杜尼执导并主演,布兰登·斯克莱纳、珍妮·斯莱特出演,讲述一个花店女子与帅气医生邂逅并相爱,但逐渐发现对方不为人知的一面,并陷入爱情的两难抉择。
詹姆斯·古恩执导新《超人》电影拍摄杀青

詹姆斯·古恩执导的 DC 新《超人》电影正式杀青,导演在社交平台上发布了和演员们的合影。
古恩表示,他拍摄的是一部讲述「一个好人在一个不总是善良的世界里」的电影,而他在片场却能一直感受到爱和善意,他对剧组人员表达了感谢。
电影将由大卫·科伦斯韦饰演超人克拉克·肯特,瑞秋·布罗斯纳安、尼古拉斯·霍尔特等将出演,将聚焦在超人调和自己的氪星人起源和堪萨斯农场成长经历的故事。电影已经定档 2025 年 7 月 11 日在北美上映。
消息称舒淇正在筹备首部执导电影

有爆料称,演员舒淇正在为自己执导的首部电影做准备。
电影男女主角的人选已经敲定,将由邱泽和歌手 9m88(汤毓绮)担任,据传将于 8 月 3 日开机拍摄。目前没有更多信息。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
from 爱范儿 https://ift.tt/SLIX8oc
via IFTTT