上周 OpenAI 率先深夜放出大招,推出的 GPT-4o mini 上演了「以小胜大」的好戏,一脚将 GPT-3.5 Turbo 踹「退役了」,甚至在大模型竞技场 LMSYS 上还强过了 GPT-4。
到了本周 Meta 发布的 Llama 3.1 大模型,如果说第一梯队的 405B 尺寸还在意料之中,那么上演「以小胜大」的 8B 和 70B 尺寸版本则带来更多惊喜。
而这或许不是小模型竞争的终点,更可能是一个新的起点。

不是大模型用不起,而是小模型更有性价比
在 AI 圈的广袤天地里,小模型始终始终有着自己的传说。
往外看,去年一鸣惊人的 Mistral 7B 刚一发布就被誉为「最好的 7B 模型」,在多项评估基准中均胜过了 13B 参数模型 Llama 2,并在推理、数学和代码生成方面超越了 Llama 34B。
今年微软也开源最强小参数大模型 phi-3-mini,虽然参数量仅有 3.8B,但性能评测结果远超同等参数规模水平,越级比肩 GPT-3.5、Claude-3 Sonnet 等更大模型。
往内看,面壁智能在 2 月初推出只有 2B 参数量级的端侧语言模型面壁 MiniCPM,用更小的尺寸实现更强的性能,性能超越法国当红大模型 Mistral-7B,被称为「小钢炮」。

前不久,仅有 8B 参数大小的 MiniCPM-Llama3-V2.5 在多模态综合性能、OCR 能力等方面也超越了 GPT-4V 和 Gemini Pro 等更大模型,也因此遭到了斯坦福大学 AI 团队的抄袭。
直到上周,深夜炸场的 OpenAI 推出被其描述为「功能最强、性价比最高的小参数模型」——GPT-4o mini,以浩荡之势将众人视野拉回到小模型之中。
自打 OpenAI 将全世界拽入生成式 AI 的想象以来,从卷长上下文、到卷参数、智能体、再到如今价格战,国内外的发展始终围绕一个逻辑——通过迈向商业化从而留在牌桌上。
因此,在一众的舆论场中,最引人注目的莫过于降价的 OpenAI 似乎也要入局价格战了。
可能很多人对 GPT-4o mini 的价格没有太清晰的概念。GPT-4o mini 每 100 万输入 token 价格为 15 美分,每 100 万输出 token 价格为 60 美分,比 GPT-3.5 Turbo 便宜超过 60%。
也就是说,GPT-4o mini 生成一本 2500 页的书,价格只需要 60 美分。

OpenAI CEO Sam Altman 也在 X 上不免感慨,两年前最强的模型与 GPT-4o mini 相比,不仅性能差距巨大,而且使用成本高达现在的 100 倍。
在大模型价格战愈发激烈的同时,一些高效经济的开源小模型也更容易受到市场的关注,毕竟不是大模型用不起,而是小模型更有性价比。
一方面,在全球 GPU 被爆买乃至缺货的情况下,训练和部署成本较低的开源小模型也足以让其逐渐占据上风。
例如,面壁智能推出的 MiniCPM,凭借其较小的参数能够实现推理成本的断崖式下跌,甚至可以实现 CPU 推理,只需一台机器持续参数训练,一张显卡进行参数微调,同时也有持续改进的成本空间。
如果你是成熟的开发者,你甚至可以用自己搭建小模型的方式去训练一个法律领域的垂直模型,其推理成本可能仅为使用大型模型微调的千分之一。

一些端侧「小模型」的应用落地让不少厂商能看到率先盈利的曙光。比如面壁智能助力深圳市中级人民法院上线运行人工智能辅助审判系统,向市场证明了技术的价值。
当然,更准确地说,我们将开始看到的变化不是从大模型到小模型的转变,而是从单一类别的模型转向一个模型组合的转变,而选择合适的模型取决于组织的具体需求、任务的复杂性和可用资源。
另一方面,小模型在移动设备、嵌入式系统或低功耗环境中更易于部署和集成。
小模型的参数规模相对较小,相比大型模型,其对计算资源(如 AI 算力、内存等)的需求较低,能够在资源受限的端侧设备上更流畅地运行。并且,端侧设备通常对能耗、发热等问题有着更为极致的要求,经过特别设计的小模型可以更好地适配端侧设备的限制。

荣耀 CEO 赵明说过,端侧由于 AI 算力问题,参数可能在 1B 到 10B 之间,网络大模型云计算的能力可以做到 100-1000 亿,甚至更高,这种能力就是两者的差距。
手机是在一个很有限的空间内,对吧?它是在有限的电池,有限的散热和有限存储环境下支持 70 亿,你就想象一下其中这么多约束条件,它一定是最难的。
我们也曾揭秘负责运作苹果智能的幕后功臣,其中经过微调的 3B 小模型专用于摘要、润色等任务,在经过适配器的加持后,能力优于 Gemma-7B,适合在手机终端运行。包括 Google 也计划在未来几个月内更新适合手机终端运行的 2B 版本小模型 Gemma-2。

最近,前 OpenAI 大神 Andrej Karpathy 也提出了一个判断,模型尺寸的竞争将会「反向内卷」,不是越来越大,而是比谁更小更灵活。
小模型凭什么以小胜大
Andrej Karpathy 的预测并非无的放矢。
在这个数据为中心的时代,模型正迅速变得更加庞大和复杂,经过海量数据训练出来的超大模型(如 GPT-4),大部分其实是用来记住大量的无关紧要细节的,也就是死记硬背资料。
然而,经过微调的模型在特定任务上甚至「以小胜大」,好用程度媲美不少「超大模型」。
Hugging Face CEO Clem Delangue 也曾建议,多达 99% 的使用案例可以通过使用小模型来解决,并预测 2024 年将是小型语言模型的一年。
究其原因之前,我们得先科普一些知识。
2020 年,OpenAI 在一篇论文中提出一个著名的定律:Scaling law,指的是随着模型大小的增加,其性能也会随之增加。随着 GPT-4 等模型的推出,Scaling law 的优势也逐渐显现出来。
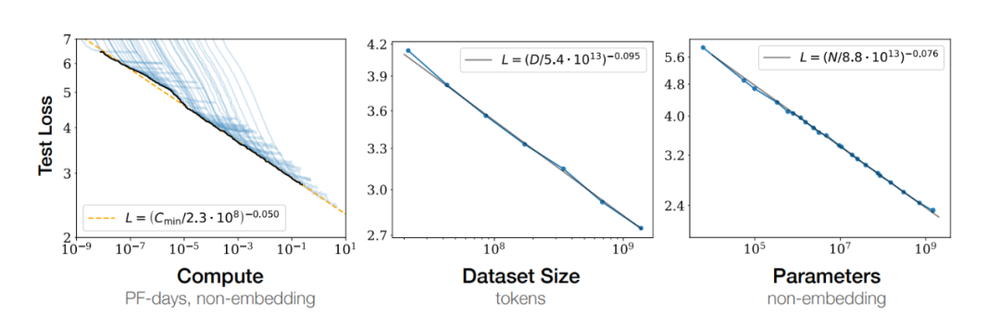
AI 领域的研究者和工程师坚信,通过增加模型的参数数量,可以进一步提升模型的学习能力和泛化能力。就这样,我们见证模型规模从数十亿参数跃升至几千亿,甚至朝着万亿参数规模的模型攀登。
在 AI 的世界里,模型的规模并非衡量其智能的唯一标准。
相反,一个精巧设计的小型模型,通过优化算法、提升数据质量、采用先进的压缩技术,往往能够在特定任务上展现出与大型模型相媲美甚至更优的性能。这种以小博大的策略,正成为 AI 领域的新趋势。
其中提高数据质量是小模型以小胜大的方法之一。
Coalesce 的首席技术官兼联合创始人 Satish Jayanthi 曾这样形容数据对模型的作用:
如果 17 世纪就有 LLM,而我们问 ChatGPT 地球是圆的还是平的,它回答说地球是平的,那将是因为我们提供的数据让它相信这是事实。我们提供给 LLM 的数据以及我们的训练方式,将直接影响其输出。
为了产出高质量的结果,大型语言模型需要接受针对特定主题和领域的高质量、有针对性的数据训练。就像学生需要优质的教材来学习一样,LLM 也需要优质的数据源。

抛却传统大力出奇迹的暴力美学,清华大学计算机系长聘副教授、面壁智能首席科学家刘知远前不久提出了大模型时代的面壁定律,即模型的知识密度不断提升,平均每 8 个月提升一倍。
其中知识密度=模型能力 / 参与计算的模型参数。
刘知远形象地解释道,如果给你 100 道智商测试题,你的得分不仅仅取决于你答对了多少题,更在于你完成这些题目所动用的神经元数量。如果用更少的神经元完成更多的任务,那么你的智商就越高。
这正是知识密度所要传达的核心理念:
它有两个要素,一个要素是这个模型所能达成的能力。第二个要素是这个能力所需要消耗的所需要神经元的数量,或者说对应的算力消耗。
相比 OpenAI 于 2020 年发布的 1750 亿参数的 GPT-3,2024 年面壁发布 GPT-3 同等性能但参数仅为 24 亿的 MiniCPM -2.4B,知识密度提高了大概 86 倍。
一项来自多伦多大学的研究也表明,并非所有数据都是必要的,从大型数据集中识别出高质量的子集,这些子集更易于处理且保留了原始数据集中的所有信息和多样性。
即使去除高达 95% 的训练数据,模型在特定分布内的预测性能也可能不会受到显著影响。

近期最典型的例子当属 Meta Llama 3.1 大模型。
Meta 在训练 Llama 3 时,喂了 15T tokens 训练数据,但负责 Llama2 和 Llama3 训练后工作的 Meta AI 研究员 Thomas Scialom 却表示:网络上的文本充满了无用信息,基于这些信息进行训练是浪费计算资源。
「Llama 3 后期训练中没有任何人工编写答案……只是利用了 Llama 2 的纯合成数据。」
此外,知识蒸馏也是其中一个「以小胜大」重要的方法。
知识蒸馏指的是通过一个大型且复杂的「教师模型」来指导一个小型且简单的「学生模型」的训练,能够将大模型的强大性能和优越的泛化能力转移给更轻量级、运算成本更低的小模型。

在 Llama 3.1 发布之后,Meta CEO 扎克伯格撰写了一篇长文《Open Source AI Is the Path Forward》,他在长文中也着重提到了微调和蒸馏小模型的重要性。
我们需要训练、微调和蒸馏自己的模型。每个组织都有不同的需求,这些需求最好通过使用不同规模并使用特定数据训练或微调的模型来满足。
设备上的任务和分类任务需要小型模型,而更复杂的任务则需要大型模型。
现在,你可以使用最先进的 Llama 模型,继续用自己的数据训练它们,然后将它们蒸馏成最适合你需求的模型规模 —— 无需我们或任何其他人看到你的数据。
业内也普遍认为,Meta Llama 3.1 的 8B 和 70B 版本是由超大杯的蒸馏而成,因此,整体性能得到了显著跃迁,模型效率也更高。
又或者,模型架构优化也是关键,比如 MobileNet 设计的初衷是在移动设备上实现高效的深度学习模型。
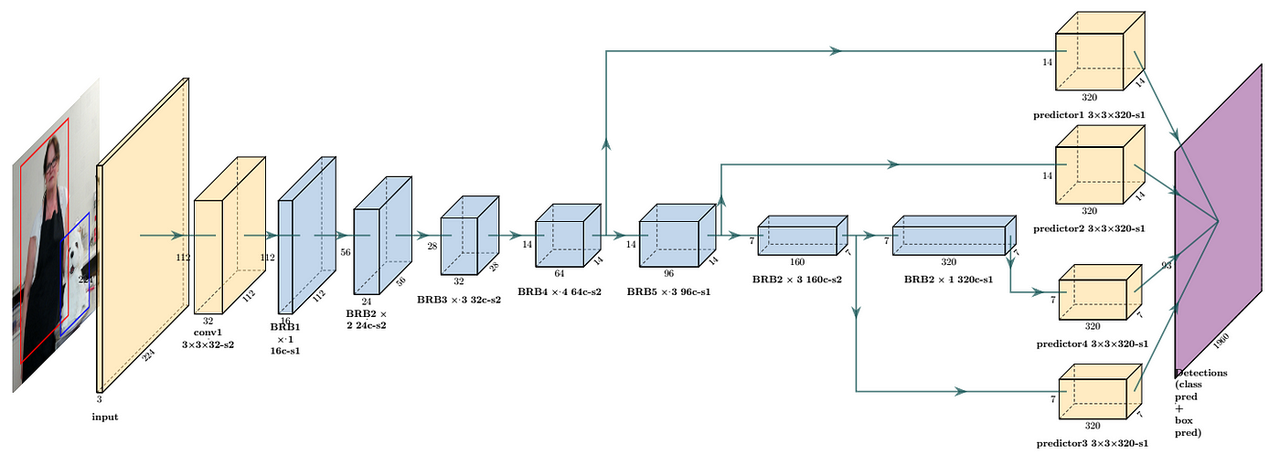
它通过深度可分离卷积(Depthwise Separable Convolution)显著减少了模型的参数数量。MobileNetV1 相比于 ResNet 在参数数量上减少了约 8-9 倍。
由于参数数量的减少,MobileNet 在计算上更为高效。这对于资源受限的环境(如移动设备)尤为重要,因为它可以在不牺牲太多性能的情况下,显著降低计算和存储需求。
尽管技术层面取得了进步,但 AI 行业本身仍面临着长周期投入和高成本的挑战,且回报周期相对较长。
据《每日经济新闻》不完全统计, 截至今年 4 月底,国内共推出了约 305 个大模型,但截至 5 月 16 日,还有约 165 个大模型尚未完成备案。
百度创始人李彦宏曾公开批评,认为当前众多基础模型的存在是对资源的浪费,并建议应将资源更多地用于探索模型与行业结合的可能性,以及开发下一个潜在的超级应用。

这也是当前 AI 行业的一个核心问题,模型数量的激增与实际应用落地之间不相称的矛盾。
面对这一挑战,行业的焦点逐渐转向加速 AI 技术的落地应用,而部署成本低和效率更高的小模型成了更为合适的破局点。
所以我们注意到一些专注于特定领域的小型模型开始冒出来,比如烹饪大模型、直播带货大模型。这些名头虽然看起来有些唬人,但恰恰是走在了正确的道路上。
简言之,未来的 AI 将不再是单一的、庞大的存在,而是会更加多样化、个性化。小模型的崛起,正是这一趋势的体现。它们在特定任务上展现出的卓越性能,证明了「小而美」同样能够赢得尊重和认可。
One more Thing
如果你想在 iPhone 上提前跑模型,那不妨尝试 Hugging Face 推出的一款名为「Hugging Chat」的 iOS App。
借助魔法和美区 App Store 账号即可下载该 App,然后用户即可在访问和使用各种开源模型,包括但不限于 Phi 3、
Mixtral、Command R+ 等模型。
温馨提醒,为了获得更佳的体验和性能,建议使用最新一代的 Pro 版 iPhone。
下载链接:https://ift.tt/cnGSTle
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
from 爱范儿 https://ift.tt/CX0d394
via IFTTT
没有评论:
发表评论