
在黄浦江边举办的 2024 世界人工智能大会里,创业者、开发者、科技爱好者们释放了比上海 38 度高温更火爆的热情,关于大模型的革命性和落地应用不相称的观点也碰撞出新的火花。
大模型的算力怎么转换成生产力?
当大模型、芯片、云计算、具身智能、自动驾驶等厂商将最新的成果聚集到一起,形成了一个中国 AI 版图的微缩景观,来到这里的人都希望从中找到一些通往 AGI 的草蛇灰线。

「这是那家很像 OpenAI 的公司」。我在智谱 AI 的展台前,听到一个参展的观众这样跟同伴介绍,这大概也是不少从业者的观感。
这家中国 AI 独角兽有着各种尺寸的通用大模型,最近发布 GLM-4-9B 模型,超越了 Llama 3 8b 模型。多模态模型 GLM-4V-9B 以 13B 的参数量做到了比肩 GPT-4V 的能力。 昨天智谱 AI 也在 WAIC 发布了第 4 代 CodeGeeX 代码大模型 CodeGeeX4-ALL-9B。
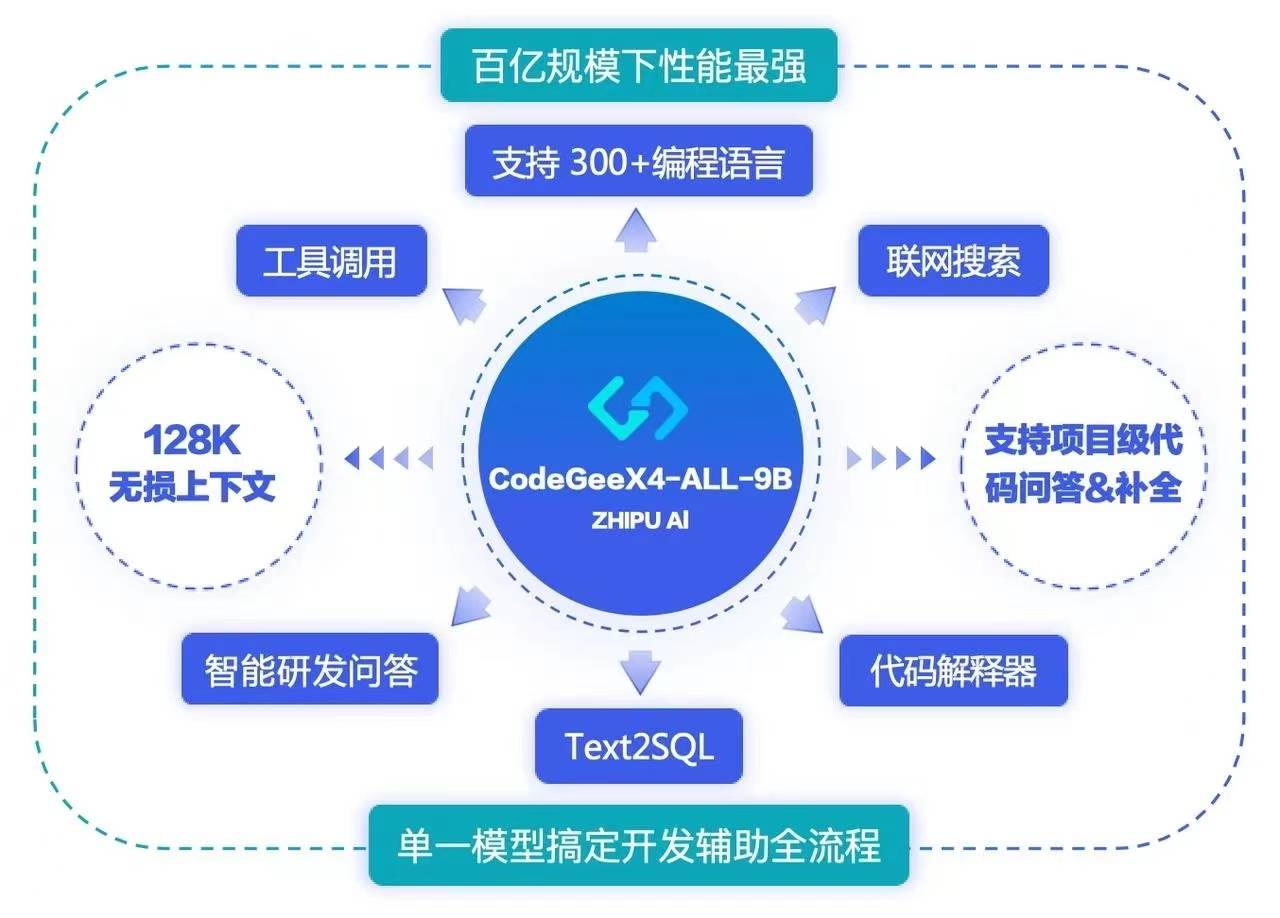
智谱 AI 商业化节奏也跑在大多对手前面,如今已经有超过 30 万个智能体活跃在清言 APP 可供使用。智谱 AI 大模型开放平台目前已经有超过 40 万注册用户,日均调用量达到 600 亿 Tokens。
智谱 AI CEO 张鹏认为,当下因大模型而掀起的 AI 热潮和之前有所不同,在过去,AI 技术解决了一些实际问题,但如今的大模型发展带来了更重要的类人认知能力。
大模型能够在一个模型上提供泛化能力,解决一系列场景和应用的多样需求,从而解决成本和收益的平衡的问题,这是它的本质特点。
张鹏也在现场接受了 APPSO 等媒体的采访,谈论了对大模型落地、超级应用和技术未来曲线等话题,涵盖了从大模型研究到商业化的部分关键问题。
以下是对话实录,中国 AI 公司是怎么将大模型落地的,可以从中看到一些侧写。
大模型落地,别只盯着超级应用
Q:关于大模型的 TPF(Technology-Problem Fit),智谱是怎么将技术跟产品结合,然后去落地的?业界对此还没有达成共识。
张鹏:我从来不觉得这个事情需要争议,任何一项新的技术的落地,它都需要一个周期,这是自然规律,但这个周期有长有短,而且在大模型这样的革命性技术落地过程,肯定会有更大的挑战,有更多需要我们解决的问题。
从客观历史来讲,这次技术革命的落地已经够快了,但正是由于它太快了,所以大家对这个事情的认知水平还是有一些参差的,分布的方差比较大。
技术还需要快速地去迭代和更新,但是在应用上我们也不能等它完全成熟再去落地。
Q: 能分享一些大模型落地的经验吗?
张鹏:首先你要深刻理解认知这个模型的能力。要尝试去把握它的优势,去避免利用它的短板,比如说你让模型去算很精确的物理模型或者是数学公式,它就像人的大脑一样,它不擅长,所以你就不要去苛责。
比如用它来代替原来你用得很习惯的计算器,就不太合适,所以你要找到合适的角度发挥它的优势,不要去背道而驰,或者挡住它发展路径的空间,可能随时会被模型能力的迭代碾压掉。
Q:最近大家讨论的 AI 超级应用,离我们还有多远?其实现在超过千万级日活的 AI 应用都很少。
张鹏:大家对超级应用的定义非常模糊,每个人都有自己的一套想法,ChatGPT 算不算超级应用呢?
Q:看它跟什么类比。
张鹏:对,你总要有个类比。ChatGPT 已经是历史上月活破亿最快的产品了,如果这都不能称之为超级应用的话,什么可以称为超级应用?
不要过早地只看这个结论,观察发生的过程你就会发现它已经发展得非常快了,所以保持一点耐心,超级应用的出现不完全是一个技术驱动的事情,还要考虑很多因素比如市场和用户是否准备好。
我再举一个简单的例子,Google 搜索引擎的用户量够大了,它从成为世界第一的搜索引擎,到它探索出成功的商业落地的路径,你猜它花了多长时间?6 年,就现在的 Meta,原来的 Facebook,同样也花了 6 年。
Q:从移动互联网出现到微信抖音也花了更长时间。
张鹏:所以大家为什么不能再等一等呢?不如多尝试一下它。就像我们小时候玩打砖块的游戏一样,你想要瞄准缝隙把它打到一个很精准地打到一个缝隙里去,这件事情首先你得找到缝隙在哪儿?路径在哪儿?
很多事情要前赴后继地去探索,这个过程就很重要,不要只看到最终的结果,更重要的是我们采取行动,我觉得这才是目前大家更应该关注的事情。
Q:行业里有人认为提到未来几年可能会落地创新应用,他给了一个很明确的时间是 3 年左右,您怎么看?
张鹏:也许明天就有,我刚才说了这个事情它需要综合考量不同因素,一个是技术本身的成熟度,第二个是市场和用户本身是否准备好。第三个是需求的发掘,然后甚至还加上有一点点运气,变量太多,很难用我的大脑这么简单的一个神经网络去预测这种事情。
Q:最近有一个热议观点,说没有应用的基础模型一文不值。
张鹏:本身这件事情也分两个层面,首先技术的创新这件事情它本身就有意义,因为我们有这么多的科研人员,也在不断探索人的智能到底是因为什么产生的,我们怎么样让机器去接近人类的智能,它的意义本就非常重大。
第二个层面。如果说这件事情探索的结果,是我们能够把它工程化、产品化,把它变成一个更有价值的生产力,它的意义就会更大。
这件事情它不是二选一,是一个串联的问题。应用当然很重要,我们确实是希望在当下把技术能转化成更多新的生产力,但并不代表说我们去追求技术的创新和本质上的探索就没价值。不要走向任何一个极端,它们是互相促进的关系。
Q:还有一种观点认为开源模型并不合适大多数的应用场景,商业化的闭源模型是最能打的。前段时间智谱也发布了 GLM-4 开源版本,您怎么看模型开源和闭源的问题?
张鹏:我们一直认为开源和闭源它们本质的目标和意义是不一样的。闭源更多是从商业化的角度来考虑,它是一个商业路径,然后提供更好的服务更安全的产品。而在大模型开源这件事情上,它的目的主要是为了丰富生态,促进技术的创新。
任何一项技术如果单纯走向一个封闭而且垄断的发展路径,要么就是活力不够,要么就是会变成一个对整个生态不太友好的一种状态。就像生物圈一样,必须要保持一定的多样性,开源更多的是为了保持技术的创新和技术多样性,让开源社区也能够投入到技术的核心里来。
Q:您此前提过智谱的商业化重心在 ToB 上,ToB 客户现在主要聚焦哪些行业?你们具体帮助客户做什么方面的应用?
张鹏:只是说我们现在目前主要的收入来源还是在 ToB 端,但并不代表说我们商业化路径只有 ToB 这件事。
目前我们在服务的 B 端客户大概覆盖了 10 多个行业,包括像金融、教育、互联网,然后零售、汽车、能源、传统制造业等。
我们目前帮助行业性客户落地,我主要还是通过几种路径。
首先我们有自己的开放平台,可以帮助我们的客户快速接入模型的能力,成本也比较低,快速地去尝试创新,然后去更新自己,迭代自己的产品和 AI 赋能。
第二种对于针对一些大型的对数据安全和要求、私有化要求比较高的,我们会提供云端的私有化的方案和本地的私有化的方案,然后再针对一些场景特别明确,然后还有中小型的这种企业落地的场景,我们会提供比如软硬件一体的解决方案。
目前我们的开放平台,现在已经有超过 40 万的企业用户,其实也包括一部分小的开发者团队,在我们平台上注册和使用我们的模型 API 的,现在每天的服务量也超过了 600 亿 token 的服务量,增长非常快速。

Q:最近 OpenAI 停止了对中国开发者提供 API 服务,智谱很快推出了搬家服务,目前用户迁移过来的情况怎么样?
张鹏:从我们的观察来看是有增量的,但是整个的市场的响应有一个过程,我也问了一下友商的情况,其实大家都观察到了增量。
Q:接下来有没有出海打算?
张鹏:我们已经在布局国际业务线,现在正在已经有一些业务在洽谈。
大模型下一步的发展在哪里?
Q:GPT-5 一直跳票,业界认为大模型的迭代曲线在放缓,Scaling Law 到底是不是走到尽头了?
张鹏:早期的 Scaling Law 非常的简单,单纯只关注模型的参数量,但是后来大家发现 Scaling Law 里面的内涵,它参数量的大小只是其中一个因素和变量,它还包括了后来又包括了比如说训练用的数据量,token 的数量,然后再后来又发现跟计算量也有关系,所以 Scaling Law 本身的内涵也在不断的变化。
更接近 Scaling Law 真相的可能是计算量,计算量融合了算力和数据,还有参数规模,最终得到的可能一个综合性变量,这样更能代表 Scaling Law。从计算量的角度来看,我们认为 Scaling Law 还是有效的。
有一个侧面的例子来证明这件事情,就是美国现在限制 AI 技术的出口,他的限制标准不再是比如说芯片的算力,或者模型的参数量、数据量,而用的是计算量,就 10 的 24 次方画一条线,如果这个模型的计算量超过这条线,就不允许,所以你看他也是在往更贴近真相的这个方向在走。
但它的本质是什么?我们还在探索,因为 Scaling Law 本身就是一个观察到的现象,得到的一个规律,它并不是一个真理的内涵是什么。
Q: 接下来智谱 AI 更倾向于端侧还是云端大模型?
张鹏:我们相信目前大模型的路径是迈向通用人工智能,甚至是超越人的这种超级智能,这是目前看起来比较可靠的路径,但是我们并不会局限在云端或者是端侧这样的选择上。
我们相信这个技术的发展它有自己的阶段性,在某个阶段,比如说现在云端可能因为算力等原因,它的智能水平是最高的,如果我们想要向下一个阶段的通用人工智能或者超级人工智能前进。可能还是集中在云端的提供这种更强的能力。

▲WAIC 上的人形机器人.
但是在某些特定的场景下,比如说在端侧手机上、在汽车上、在机器人上,可能就需要端侧的算力和端侧的模型去配合云端,它可能是一个端云结合的这种模式,可能未来我们在手机上就能实现像现在云端这么聪明的智能,但是这涉及很多综合因素,芯片、算力能源等等一系列的问题。
任何技术都是有阶段性的,在这个阶段方案是这样,但是从更长的时间尺度来看,它(端侧和云端)是不是终极答案?肯定不是,未来一定还会往前再发展。
Q:您觉得大模型下一步的发展在哪里?
张鹏:目前大模型在语言和文字能力上已经接近甚至略微超过人类的平均水平了。下一步,我们对它希望可以用一个词来形容,「脱虚向实」,就是不再局限于成为一个缸中大脑,让它能够走入到实际的生活和工作中去创造实际的生产力。

要实现这个目标其实除了语言能力,还要需要很多其他的能力,比如说视觉能力,听觉的能力,还有这种动手动脚的长出手脚的执行能力,我们希望它会变成一个多模态的模型,这个模型它能够理解人的意图,把人的意图拆解成一些逻辑性的执行步骤,并且能够使用工具连通物理世界去完成这些工作。
既然我们希望它具备更强的干涉物理世界的能力,那么安全就变得更重要,防止它去在现实的物理世界当中做一些危害性的东西,这在数字世界也是一样,我们需要在安全性和对齐上做更多事情,我们把它叫做超级智能和超级对齐。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
from 爱范儿 https://ift.tt/uXaEV3C
via IFTTT
没有评论:
发表评论