
2013 年的时候,自动驾驶还是一个非常前沿和性感的概念,一如当下的 AGI,前几年的元宇宙,在互联网公司如火如荼的时代,腾讯每年都会举办一场 WE 大会,来聊一聊那一些星辰大海的话题,比如基因编辑、脑机接口、宇宙探索等等。
我第一次接触「自动驾驶」的概念,就是在 2013 年第一届腾讯 WE 大会上,当时有嘉宾抛出了如下观点:
- 技术问题不难解决,难以解决的是法律问题。
- 在十年之内,消费者是可以买到无人驾驶汽车的。
- 如果机器它做的判断正确率达到 95%,那可能还是要比人好、比人快。
十年之期已到,这些话算是大致应验,当萝卜快跑已经在多个城市大规模上路,主流新势力品牌的高端车型具备高阶智能驾驶能力,以及特斯拉 FSD V12 版本的推送,还有特斯拉 RoboTaxi 即将发布,自动驾驶技术正从 L2+ 级别往 L4 级别迈进,「车坐不开」变得并不遥远。
等一下,当我拿出这张图,阁下该如何应对?

这是广州城区日常交通状况的一个普通场景:机动车道不仅跑着海量乱窜的两轮电瓶车,甚至龟速的电动轮椅也跑在机动车道上。
此时,智能驾驶的优势和挑战就一起体现:优势是智能驾驶没有情绪,不会生气不会路怒;挑战是龟速电动轮椅和乱窜侵入机动车道的两轮电瓶车对于智能驾驶来说,是很不好预测和处理的场景。
实际上,十年前预测自动驾驶发展大多基于一个逻辑:路上的车和人都遵守交规,红灯停绿灯行,机动车道不会出现害人精。
但当厂商们交付带智能驾驶功能的汽车到消费者手上时,汽车面对的情况就是上面这张图:马路是我家,交规去 TM。
经典智驾逻辑:「感知 — 规划 — 控制」
当下主流的智能驾驶方案,无论是高精地图方案,还是无图方案,都依赖于大量工程师根据各种各样的道路场景去编写规则,以期实现穷举所有道路状况和对应措施,实现尽可能的智能驾驶行为。
不过现实道路情况不仅错综复杂,不可能被穷举,同时现实世界也在不断变化,随时有新的道路场景出现。因而,此前智能驾驶研发是一场「无限战争」。
比如说,环岛进出这个场景,在 7 月份之前,还没有几家车企能够攻克,因为场景复杂,感知受限,规划决策困难。
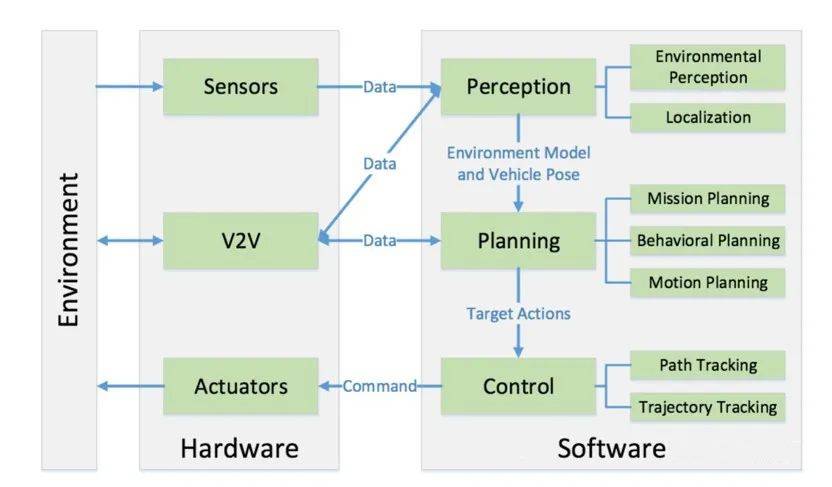
简单来讲,在特斯拉 FSD V12 版本采用「端到端」技术方案之前,几乎所有的智驾方案都可以归结为「感知 Perception — 规划 Planning — 控制 Control」三个大模块,这一套流程覆盖各种各样的场景,比如经典的三分法:高速场景,城区场景和泊车场景。
这几个大场景又可以细分细分再细分,智驾工程师们针对场景来编写规则代码,汽车的激光雷达、毫米波雷达和摄像头还有定位系统一起协作,感知和记录道路、环境和位置信息,然后 BEV(Birds-Eyes-View)技术或者 OCC(Occupancy Network)技术或者其他的技术来把这些传感器获取的信息形成能被智驾系统理解的「真实世界的虚拟投影」,智驾系统再根据这种「世界投影」规划出合理的行进路线和运动规划,进而得出控制决策,最后汽车响应决策,就形成了「减速,左侧变向,提前走左侧掉头车道,紧急刹车躲避路中间乱入的两轮电瓶车,继续前进,调头」这种智能驾驶行为。
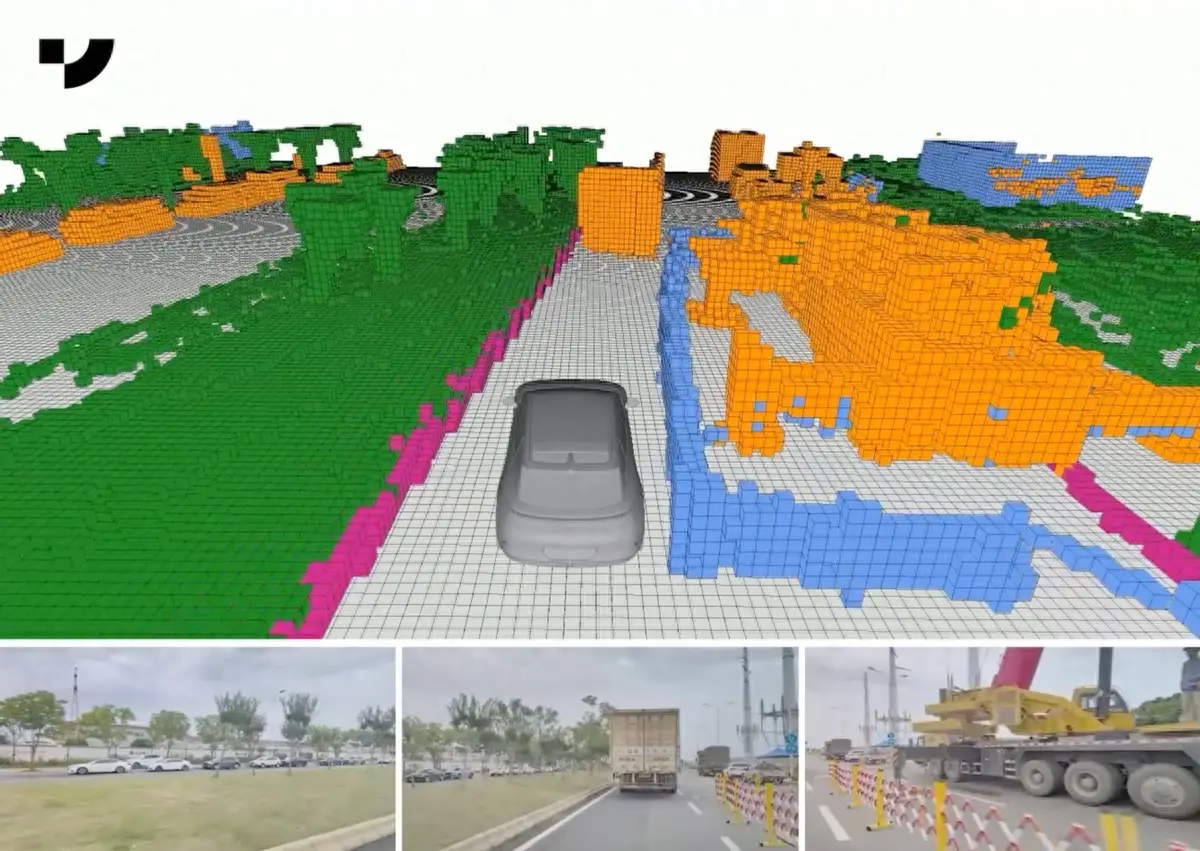
▲ 极越汽车 OCC 占用网络示意图
如果智能驾驶使用到了 OCC 占用网络技术,那么我们就可以打个比方,在智驾系统里,外部世界就像《我的世界》那样,是由一个个方块(体素)组成的,如果道路前方一片坦途,那理论上路上就没有方块,车就可以大胆往前走,如果前方有一个静止的小方块,那可能是雪糕桶跑到路中间了,如果右侧有缓慢移动的长条,可能就是行人,如果是左边车道快速移动的超大长方形块,那可能是大货车……
在这个「感知 — 规划(决策)— 控制」的大逻辑下,不管是此前的基于高精地图的方案,还是后续更依赖于多种传感器融合和高本地算力的无图 NOA(自动导航辅助驾驶)方案,都没有脱离这个基本逻辑,研发的框架和工程师的工作,也都是在各个模块里各司其职。
直到,「端到端」的出现。
什么是「端到端」?
印象中有三次人工智能的标志性事件,引起了广泛的社会讨论。
第一次是 1997 年 IBM 的国际象棋机器人「深蓝」战胜了国际象棋大师卡斯帕罗夫,但站在如今的时间点看「深蓝」,就会觉得它并非那么智能,它只不过是存储了巨量的开局和残局棋谱,然后搭配高效的搜索算法和评估体系,选出最合适的下法。
也就是说,深蓝在下棋的时候,中间的决策对于人类来说是可解释的,逻辑清晰的。

接着就是在比国际象棋更复杂的围棋领域,DeepMind 的 AlphaGo 赢了李世石和柯洁,宣布人工智能的水平远超所有人类棋手。
AlphaGo 的逻辑不是搜索匹配棋谱,毕竟围棋的棋盘格子数和棋子数量远超国际象棋,蕴含的可能性太高,现在的计算机没法算出其中所有的可能性。但基于神经网络的深度学习,AlphaGo 一来可以自我学习自我进化,二来可以知晓下一步怎么下更接近胜利,对于人类来说,AlphaGo 的下法和人类思考逻辑完全不同,但中间发生了什么,人工智能专家是知晓其逻辑的。
接着就是 ChatGPT 的出现,大语言模型技术在输入和输出之间,存在着人工智能专家都难以解释的「黑盒子」,人类无法准确解释问问题和 ChatGPT 回答之间,具体发生了什么。
以此做个比喻,智能驾驶技术此前基于「感知 — 规划(决策)— 控制」的研发逻辑,类似于 AlphaGo ,AlphaGo 的卷积神经网络(CNNs)能够处理棋盘的二维结构,提取空间特征;而价值网络和策略网络能够提供规划和决策,此外还有强化学习和蒙特卡洛树搜索技术能优化决策。
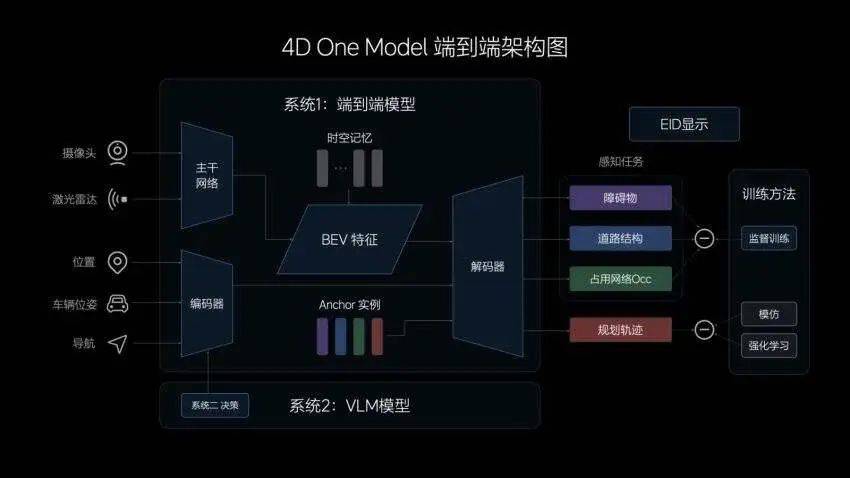
▲ 理想智驾端到端架构图
而智能驾驶技术里的「端到端」,就类似于 ChatGPT 背后的大语言模型技术,从原始传感器数据(如摄像头、毫米波雷达、激光雷达等)到最终的控制指令(如加速、刹车、转向等)的全流程处理。当然,现阶段这种直接控车的方式还是太激进,所以像是理想的端到端就只输出轨迹,没到控制,到车辆控制之前还是有很多约束和冗余措施。这种方法的目标是简化系统架构,通过一个单一的神经网络或模型完成整个任务,背后不再依赖海量的场景规则代码,是完全不同的技术方向。
正如大语言模型之前强调的是参数量的大一样,端到端背后的多模态模型也存在这样一个量变产生质变的过程,特斯拉在 FSD V12 上率先使用了端到端技术,马斯克就这么说:
用 100 万个视频切片训练,勉强够用;200 万个,稍好一些;300 万个,就会感到 Wow(惊叹);1000 万个,那就难以置信了。
但经常使用 ChatGPT 或者其他生成式 AI 工具的人就会发现,这些工具并不可靠,经常信誓旦旦地输出错误答案,谓之「幻觉」。
电脑上的 AI 工具瞎回答问题一般没啥灾难性后果,但智能驾驶事关生命安全,一个「端到端」搞定驾驶行为,还需要更多的验证和保险措施,这是个技术问题,更是个工程问题。

对话理想智驾团队:「端到端」才是真正用 AI 做自动驾驶
经历了前面长篇累牍的背景介绍之后,终于可以切入正题:借着采访理想智驾团队的机会,来聊一聊「端到端」如何从理论,到上车?
理想智驾研发副总裁郎咸朋告诉爱范儿和董车会:
我们今年春季战略会上有一个重要反思,就是我们太过于追求竞争,比方说老是盯着华为什么的,它开多少城,它的指标是多少,其实单纯的盯指标,比如说我比华为好一点,或比华为差一点,并不能代表用户真正的需求。
回归到用户的开车需求上来看,真正的用户需求不是接管率指标低到多少,用户需要的是智驾像老司机那样去开车,而这种拟人化的需求依靠原来规则化的模块化的研发架构很难实现。但理想内部预研的「端到端」会做得更好。
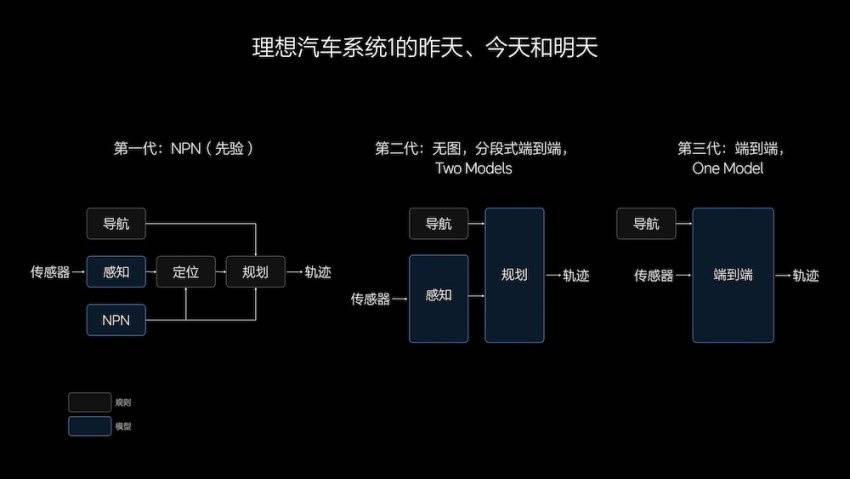
基于此,在一年之间,理想的智驾技术方案经历了三代调整:从有图到 NPN(神经先验网络)到无图,再到端到端。
郎咸朋这么解释端到端本质上的不同:
端到端它表面上看是一个大模型替代几个小的模型,其实它是一个分水岭,从端到端开始,才是真正地用人工智能的方式来做自动驾驶,前面其实还不是。
因为它是数据驱动的,由算力配合上数据,配合上模型,是高度自动化的自我迭代过程,这个过程迭代的是模型或系统自己的能力。那么之前我们做了什么呢?我们做的都是系统各种各样的功能,上下匝道的功能或过收费站的功能。
功能和能力,是有很大区别的。
但实际上,理想智能驾驶夏季发布会上发布的下一代自动驾驶系统是「端到端+ VLM(视觉语言模型)」双系统方案。

既然前提是要把智驾做得像老司机驾驶,尽可能拟人化,那就得考虑人究竟是怎么做事儿的,这里的理论依据是诺贝尔奖获得者丹尼尔·卡尼曼在《思考,快与慢》中的快慢系统理论:
人的快系统依靠直觉和本能,在 95% 的场景下保持高效率;人的慢系统依靠有意识的分析和思考,介绍 5% 场景的高上限。
理想「端到端+ VLM」双系统里的端到端就是快系统,有日常驾驶场景里快速处理信息的能力,而 VLM 视觉语言模型有面对复杂场景的逻辑思考能力。
这个快系统的究竟有多快呢?
理想智驾技术研发负责人贾鹏说:
现在我们端到端延迟相当于是传感器进来到控制输出 100 多毫秒,不到 200 毫秒,以前分模块大概得到 300 多将近 400 毫秒。
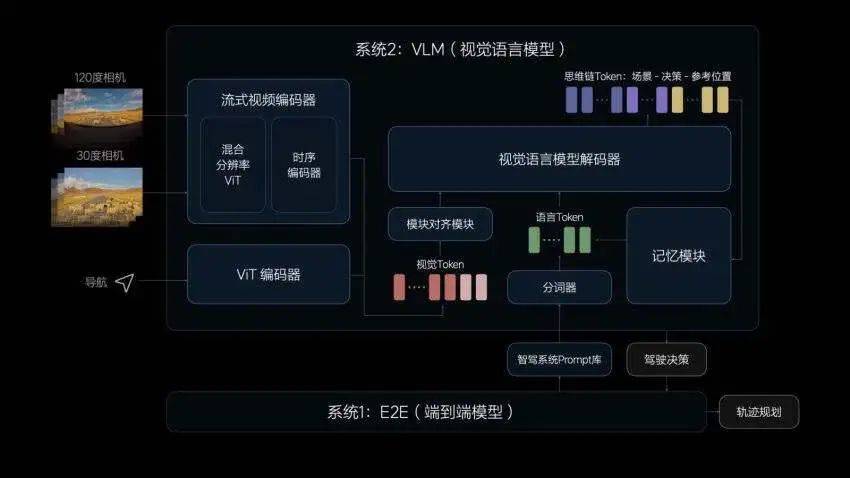
这个慢系统为什么又是必要的呢?
郎咸朋解释说:
我们现在正在探索它(VLM)的一些能力,它至少在刚才说的主路、辅路车道选择这块有一些价值,如果没有它,也不会出安全问题。我们在 L3 级别智能驾驶起主要的支撑作用还是端到端,代表这个人正常的行为下的驾驶能力。
但到了 L4 级别智能驾驶一定是 VLM 或者大模型在这里面起到更重要的作用,可能 90% 以上的时间它不起作用,但它起作用这些内容,是决定这个系统到底是 L3 级别还是 L4 级别的一个关键点,VLM 是能真正的能去应对这种未知的场景。
理想并不是一个端到端模型就完事儿,而是采用了更稳妥的双系统方案来覆盖全场景,端到端负责让驾驶行为更拟人,更像老司机,而 VLM 视觉语言模型托住下限,更能拔高上限,有望达到更高级别的自动驾驶。
再深究一下,和原教旨主义的端到端最后还要负责汽车控制不同,理想的端到端其实也没有直接能控车,而是到了输出轨迹这一层级。
贾鹏说:
我们的端到端模型是到了轨迹,轨迹之后加一些安全兜底,因为在模型没有达到上限之前,还是要有一些处理的东西,比如说猛打方向盘这样的事,给他兜掉。
而在实际的智能驾驶过程中,两个系统也是同时工作的,贾鹏具体解释了两个系统如何共同协作:
这俩系统一直都在实时运行,一块跑是端到端,因为模型小一些,它的频率比较高,比如跑个十几赫兹。另外那个模型规模参数量就大的多,是 22 亿参数,目前能跑到大概 3~4 赫兹之间,其实也是一直在跑。
VLM 发决策结果给参考点,比如说在 ETC 进高速的时候,其实车很难判断要走哪个道,我要走人工还是走 ETC?这个时候 VLM 也一直都在,如果想去选 ETC 可以走 ETC 这条道,如果想走人工可以走人工这条道,只不过它是把决策结果和参考的轨迹扔给端到端模型,端到端模型推理后,再采用这个信息。
其实 VLM 视觉语言模型是个辅助信息,最终的轨迹结果是模型推理的结果,它是有一定概率被采纳的。
为什么端到端能够在智能驾驶领域掀起如此大的浪潮?还是因为它背后巨大的可能性,以及在找「终极答案」上的指向性意义。
简言之,在这套方案上,大家都还远远没有摸到能力的天花板,技术探索和工程实践,进入到了旷野区。
贾鹏进一步解释双系统的原理,以及可能性:
其实人就是双系统,虽然物理结构上并不是那么明确的双系统,但是人的思维方式就是双系统,所以我们当时有一个想法是在端到端的基础上再加一个真正有泛化能力,有逻辑思考能力的一套系统,自然而然就想到了 VLM。
虽然 VLM 不直接控车,但是会提供决策。
再朝后这套东西怎么发展?可能随着算力的增加,比如特斯拉 FSD 12.3 到 12.5 版本,参数提高了 5 倍,可以支撑足够大的模型。
我觉得以后两个趋势,第一是模型规模变大,系统一和系统二现在还是端到端加 VLM 两个模型,这两个模型有可能合一,目前是比较松耦合,将来可以做比较紧耦合的。
第二方面也可以借鉴现在多模态模型的大模型发展趋势,它们就朝这种原生多模态走,既能做语言也能做语音,也能做视觉,也能做激光雷达,我觉得这是将来要思考的事情。
我们这套范式应该能够支撑我们做到(L4 级自动驾驶),因为在机器人具身智能上我们已经看到它的应用雏形,参考人的思维过程,这套东西可能就是我们心目中想追求的终极答案。
终极答案的意思是我们用这套理论和这套框架去做真正的人工智能。

不过在聊终极答案之前,贾鹏解释了为什么只有端到端能够解决「环岛进出」的智驾难题:
如果是分段式的(智驾方案),前面是个感知,要给规控去做各种假设,做个掉头,还得把掉头线拟合出来,不同的路口的掉头还不太一样,曲率都不太一样,所以你很难做到一套代码就可以把所有环岛掉头搞定,种类太多了。
关于环岛这件事,也有一个好玩的故事,在我们(模型数据包含)大概 80 万 clips(视频片段)的时候,还过不了环岛,后来突然发现一天我们(喂了)100 万 clips 它自己能过环岛,我觉得是 100 万(视频片段)里头刚好有一些环岛数据放在里面了。
模型确实很厉害,你喂了什么数据他就能学会,这是模型的魅力所在,就像 ETC,我觉得如果你开我们现在端到端的版本,会发现其实 ETC 它自己能过,但是问题是它现在不知道我要走哪条道,到底是走 ETC 道还是走人工道,他自己会随便乱选一个,会让你觉得不太安全,我们后面想做的就是 VLM 可以给他这个指引,因为 VLM 是可以理解语文字,理解 LED 指示灯的。
关于端到端理论部分的 What 和 Why,至此也有了大概的轮廓,有了数据和模型之后,就是真正地上车了,也就是 How,这才是真正的大考环节。

▲ 理想汽车制造车间
「训练端到端模型,跟炼丹没什么区别」
郎咸朋给爱范儿和董车会讲了一个训练端到端模型里很离奇的小故事:
今年比较早期的时候,刚开始做项目,我们发现模型训练出来,平时开着还都 ok,但等红灯的时候,车的行为就比较怪异,它总是想变到旁边的车道,我们不知道为什么。
后来明白我们在训练端到端模型的时候,删除了很多在红灯之前等待的数据,我们觉得等了几十秒或者一分钟,这样数据没有用。但后来发现这份数据非常重要,它教会了这个模型,有的时候是需要等待的,不是一旦你慢下来就要插空,就要变道。
这个小故事说明了,数据很大程度上决定了模型的质量,但模型的大小是有一定限制的,所以喂哪些数据去训练模型,实际上就是最核心的工作之一。

郎咸朋打了个比喻:
训练端到端模型,跟古代炼丹没什么区别。古代炼火药讲究一硝二磺三木炭,做出来的炸药威力比较大。其他配比,可能也能点个火起来。
不过对于想要训练端到端模型的车厂来说,「炼丹」只是形象地比喻,而非具体的工程落地方法,数据怎么来,怎么选,怎么训练,都是科学问题。
好在理想有一些先天优势,比如车卖得不错,销量在新势力车企里经常位居第一,路面上有 80 多万辆理想汽车在跑,每个月还能新增四五万辆,这些车提供了十几亿公里的数据。
另外,理想很早就意识到数据的重要意义,打造了关于数据的工具链等基础能力,比如理想的后台数据库实现了一段话查找当时,写一句「雨天红灯停止线附近打伞路过的行人」,就能找到相应的数据,这背后是一些云端的小模型,比如数据挖掘模型和场景理解模型。
郎咸朋甚至认为,这些数据库的工具链和基础建设能力,某种意义上(重要性)甚至大于模型的能力,因为没有这些良好的基建和数据,再好的模型也训练不出来。
底层技术方案转向,也意味着工作方式转向,当发现一个 badcase 之后,理想内部的「分诊台」系统里的模型会自动分析这属于哪一类的场景问题,给出「分诊建议」,然后回归到模型训练上来解决问题。
这里也涉及到工作方式的转变,原来解决具体问题的人,现在变成了设计解决问题工具的人。
为了提高「诊疗」效率,理想内部会同时训练多个模型,这个过程又回到了「炼丹」的概念,贾鹏解释说:
模型训练主要两个方面,一是数据的配方,类似的场景到底要加多少,能把 case 解决掉,这是一个 know-how,不同的场景对数据的要求不一样。第二点是模型的超参,加入新的数据后,模型参数如何调整,一般情况下有 5-6 版模型会同时提交训练,然后看哪一版解决了问题,同时得分也高。
同时训练多个模型,对数据库的基础建设提出了要求,也对算力有巨大要求,这个时候就该「钞能力」上场。这里理想的优势依旧是车卖得多且贵,有这新势力车企里最好的营收和正向现金流,能够支撑背后巨大的算力支出。
郎咸朋说:
我们预计,如果做到 L3 和 L4 自动驾驶,一年的训练算力花销得到 10 亿美金,将来我们拼的就是算力和数据,背后拼的是钱,还是盈利能力。

当端到端模型替代了传统智驾逻辑「感知 — 规划 — 控制」里的大部分工作时,理想相关智驾团队的最花力气的工作也集中在了「一头一尾」,头是数据,尾是验证。
除了端到端模型和 VLM 视觉语言模型这两个快慢系统之外,理想内部还有一个系统三,称之为试验模型或者世界模型,本质上这是个考试系统,来考核整个智驾系统的水平和安全性。
郎咸朋把这个考试系统比喻成三个题库的集合:
- 真题库:人在路上驾驶的正确行为
- 错题库:正常的测试和开车过程中,用户的接管,用户的退出等行为
- 模拟题:根据所有的数据,举一反三,针对特定重复问题,生成虚拟类似场景测试
比如前面提到,想要智驾开车拟人化,像老司机,那么这个真题库的驾驶行为,就得是老司机的驾驶行为,理想试验模型里的「真题库」选取了内部评分 90 分以上的司机驾驶行为,这个群体只占理想汽车司机里 3% 的比例,会看他们驾驶的平顺性,驾驶的危险程度等等,比如司机经常开出 AEB 自动紧急刹车,那他的驾驶行为就太激进了。
经过了试验模型的大量测试之后,还会有一个「早鸟用户」的测试版本,这就是有上千辆用户车获得新的智驾系统版本,以无感知的「影子模式」在真实场景和道路里去做真实的验证和测试,这比任何车厂的测试车队规模都大。
这些千人早鸟用户测试验证的数据,又会自动回传,自动分析,自动迭代训练,进行新一轮的测试和交付。
也就是说,数据获取,模型训练,试验考试和用户交付是一个充满了自动化循环逻辑的过程,人的参与度其实非常少。
按照郎咸朋和贾鹏说法,上到「端到端+VLM」之后,行业到了一个接近无人区的地方,这里既有暂时看不到这套系统能力上限的兴奋感,当然也有必须要务实的部分,比如目前只让端到端模型输出轨迹,轨迹之后的控制还需要安全兜底,再比如关于算力的思考:之前需要堆工程师数量,往后得堆显卡的数量。
没有算力,都是空想。
没有利润,算力也是空想。

再聊一下「终极答案」:理想,特斯拉和 OpenAI 的殊途同归
正如马斯克一再强调「特斯拉是一家 AI 和机器人公司,而不仅是一家汽车公司」一样,在采访中,郎咸朋和贾鹏也把理想汽车比喻成装在轮子上的机器人,也聊到了人形机器人等具身智能载体在用「端到端+VLM」的框架的应用雏形。
特斯拉的 Optimus 机器人承载了马斯克更大的愿景,当然也是 FSD 的另一种载体,因为 Optimus 机器人释放出的信息还相对较少,但它确实拥有「端到端」模型,依靠本机的摄像头和传感器输入环境信息,然后直接输出关节控制序列。
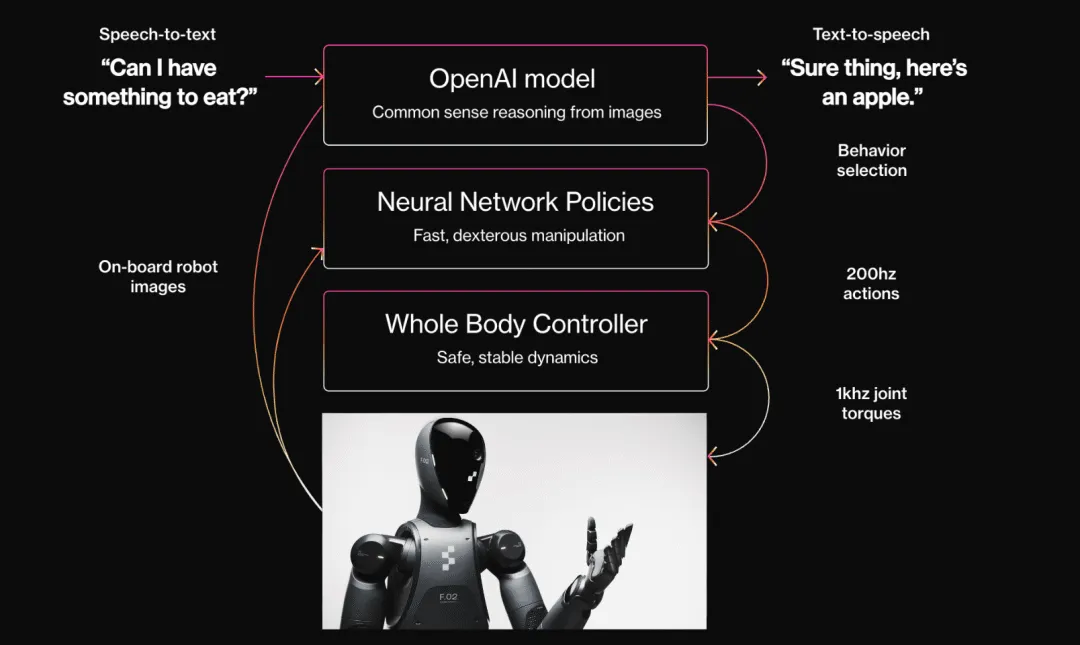
另外,OpenAI 和英伟达投资的 Figure 机器人刚刚发布了旗下的第二款人形机器人 Figure 02,并声称这是「世界上最先进的 AI 硬件」,其中 VLM 视觉语言模型是其重要能力。Figure 02 的头部、前躯干和后躯干各配备六个 RGB 摄像头,能够通过其 AI 驱动的视觉系统来感知和理解物理世界。在官方的描述中,Figure 02「具有超人的视觉」。
当然,它自然也有 OpenAI 提供的大语言模型来和人类交流。

颇为类似的是,Optimus 机器人在特斯拉的车厂里开始打工(也是训练),而 Figure 02 也在宝马的车厂里进行测试和训练,都能够完成一些简单的工作,并且都在不断进化。
虽然理想汽车,特斯拉 Optimus 机器人以及 Figure 机器人看起来相关性不大,但一旦深究起来,底层的技术逻辑,以及关于 AI 的思考,确实殊途同归,这也是「终极答案」的由来。
我们谈了几十年的人工智能,重点终于从人工,转移到了智能。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
from 爱范儿 https://ift.tt/61b4K0m
via IFTTT
没有评论:
发表评论