「漂浮在太空中的宇航员躺在云朵上,云朵变成了一遍舒适的扶手椅,扶手上有一个云朵形的遥控器。宇航员对着镜头挥手,在他的脚下,地球变成了一个令人着迷的灯光漩涡。」
也许你也曾在梦境中见过这般天方夜谭,但想要在现实中实现,估计得是 N 个世纪后的事情,但那一天到来之前,你可以先用 DALL·E 3「梦想成真」。

DALL·E 3 并不是什么陌生的工具,但还是要给不了解的朋友解释一下,DALL·E 3 是一款 AI 图像生成器,你可以将之理解为 OpenAI 版 的 Midjourney。
9 月份时候,OpenAI 宣布 DALL・E 3 将集成到 ChatGPT,堪称各自领域里几乎最强的模型合并,更重要的是,DALL・E 3 原生构建在 ChatGPT 之上,无需详细的提示词,你就可以直接在 ChatGPT 里文生图。
今日凌晨,OpenAI 官方宣布,DALL·E 3 现已向所有 ChatGPT Plus 和 Enterprise 用户开放。给个小提示,如果你不想花钱,也可以使用微软的 New Bing 来畅玩 DALL·E 3。
只有你想不到,没有 DALL·E 3 画不了
那么 DALL·E 3 的生图效果如何呢?OpenAI 在其官方博客中列举了三个标志性例子,分别涉及科学项目、网站设计、企业标志设计等诸多场景。
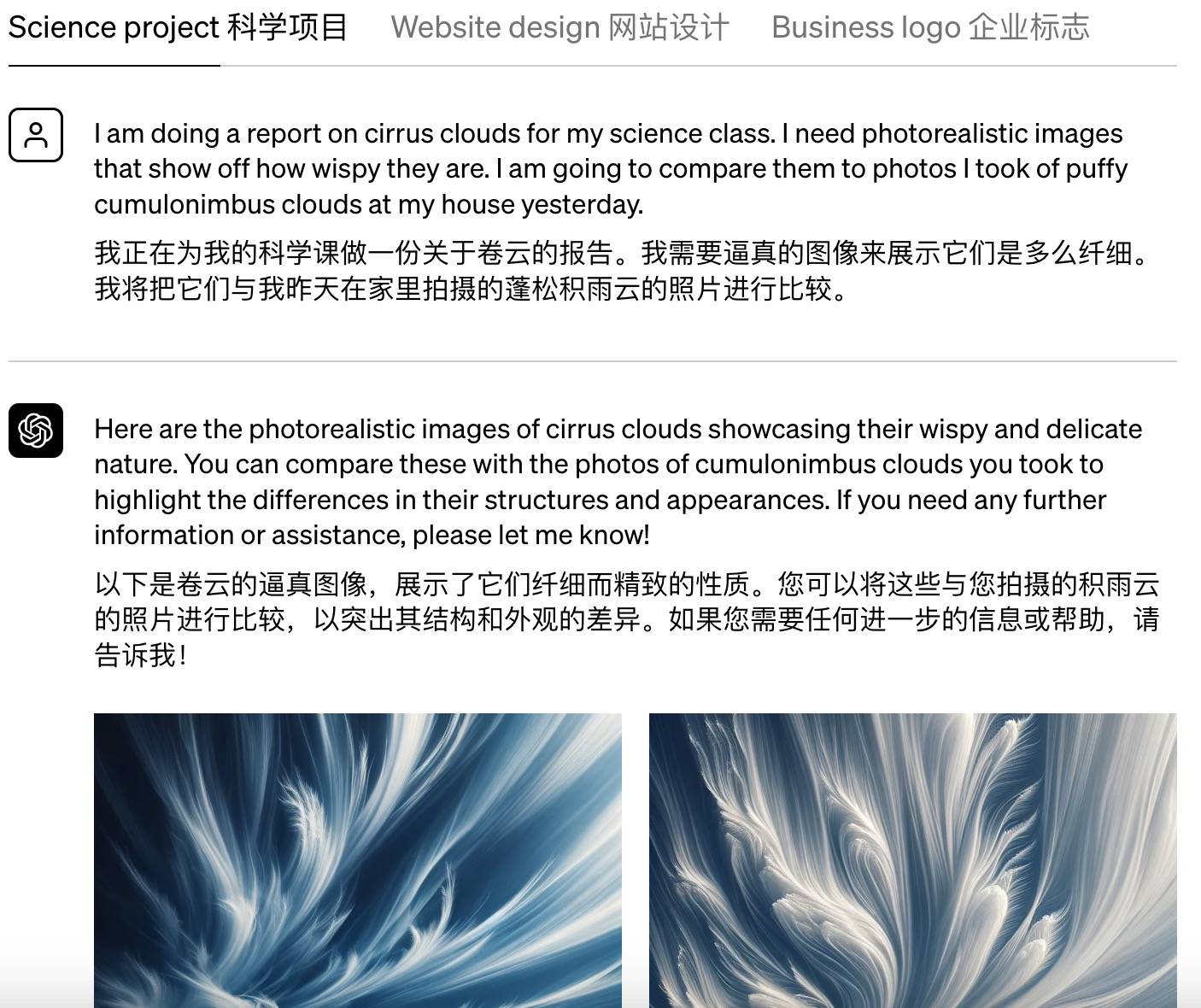
例如,倘若你需要在课堂报告中演示卷云时,你可以要求 DALL·E 3 生成足够精细的卷云图片。
又或者你是网站设计师,还在为网页设计挠头抓腮时,那么你也可以使用 DALL·E 3 来刺激更多的灵感。
至于第三个场景,则是日常生活常见的企业 logo 设计,只需要输入 Prompt(提示词),「兔子+咖啡」的设计方案就能快速地呈现在你面前。
从官方给出的最终成图来看,成图的细节保留还算完整,四张设计方案的风格能够看出比较明显的差异化,整体的水平还算中规中矩。
当然,这只是官网给出的成图,并不排除经过了「美化」,所以带着这个疑问,我们也重新按照官方给的提示词,输入进去看看实际效果?

最终的实际效果跟官图相差不大,但也有一个小「Bug」,比如第二个例子,如果光输入提示词,最终输出的却是文字,这一度让我以为我没有调整到 DALL·E 3 界面,当然,问题也不大,这不过仅仅是多了个再次确认的步骤。
琳琅满目的「Gallery 画廊」里展示了各式各样的生成图片,漫画,像素画、油画,什么样的风格都应有尽有,OpenAI 似乎想通过「Gallery 画廊」告诉用户,只有你想不到,没有 DALL·E 3「画」不了。

画是能画出来,但画得好不好才是关键,例如,我尝试让他画一幅李白穿白衣,杜甫穿黑衣的对弈图。
「Stop generating」持续了一会,给出了啼笑皆非的四幅图,第一幅图,不光衣服的颜色出错,更有趣的是,李白和杜甫变成了国际友人,下的棋还是国际象棋,显然,DALL·E 3 在理解中文的语境上还有待加强。




第二幅图对弈的紧张感倒是拉满了,但是前一幅图该有的毛病,它也没落下,至于第三第四幅图的问题也大差不差。
当然,对于 AI 图像生成器来说,调教后的结果才是其潜力所在。譬如,当我尝试让第一幅图更换为围棋以及衣服头饰后,最终生成的效果长这样!

乍一看,似乎没什么大问题,但仔细看看棋盘后,能够轻易得出一个结论:李白和杜甫把围棋下成了「拼图」?
- 1、李白对弈时,恼羞成怒,掀了棋盘
- 2、杜甫生气了,打了李白一拳
- 3、最后李白和杜甫握手言谈,继续下棋
对弈期间,有点摩擦很正常嘛,于是我让 DALL·E 3 按照下方要求生成了连环图。



满分十分,你觉得可以给这三幅图打几分?
从全量推送到现在,在神通广大的网友开发下, DALL·E 3 也被玩出了各种花样。如果你是高达玩家,你可以让 DALL·E 3 化身设计师,给你设计出最酷炫的高达图纸,清单式地展示各类零部件,然后再利用 3D 打印出来。
只不过需要注意的是,高达图纸详尽的细节看似唬人,实则也会偶尔多出几个零部件。

又或者扎克伯格与马斯克的「笼中决斗」迟迟未成行,加之 C 口 与 Lightning 口的转换也引起了许多争议,那为什么不让 Lightning 口与 C 口来一场精彩的「笼中决斗」呢?

无需提示词的背后,是 AI 在给你打工
除了 DALL·E 3 的全量推送,OpenAI 还通过一篇论文向外界揭秘 DALL·E 3 背后具体的技术细节。
为了方便你理解,我们对这篇论文抽丝剥茧后,将用一个简单的例子来解释整个技术流程。
首先 OpenAI 收集了大量的图像和对应的文字描述作为训练数据,比如图片是一只猫,那么图片对应的描述是一只橘色的猫坐在椅子上。

但「一只橘色的猫坐在椅子上」的描述比较简单,缺乏具体的细节,也没有提到这只猫是什么品种,身体特征怎样,周围环境怎么样?
为了获得更丰富的描述,OpenAI 训练了一个图像 AI 描述生成模型,也就是说,给这个模型同样的照片,它可以输出更复杂的描述:
例如,「一只橘色的猫坐在椅子上」就会变成「一只短毛布偶猫蜷缩在主人的懒人椅上,脖子上戴着一个蓝色蝴蝶结,耳朵竖立,表情很警惕。窗外阳光透进来,在地板上投下一片阳光。」

同理,有了这个描述模型,OpenAI 就可以用它去为训练数据中的每张图片生成详细的新描述。然后反过来,基于这些带有丰富细节的新描述又去训练模型,如此循环往复。
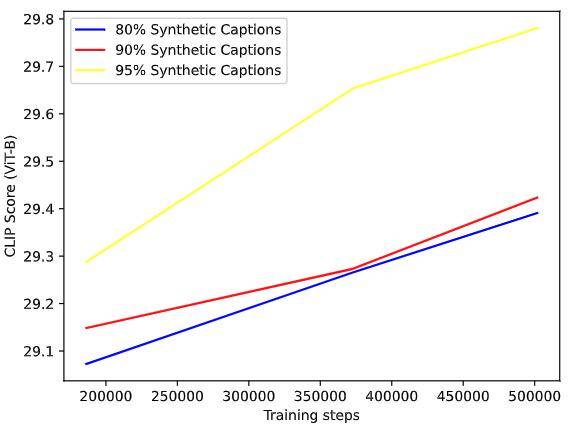
在训练过程中,研究人员也逐步增加使用 AI 合成描述的比例来测试对模型性能的影响,结果表明,使用详细的合成描述(也就是上文所说的更复杂的描述)可以让模型生成的图片质量更高,更符合输入文本的要求。
经过反复试验,研究人员发现 DALL·E 3 使用 95% AI 合成描述和 5% 真实描述的搭配,可以获得最好的效果。
此外,针对 AI 图像生成器的负面影响,OpenAI 也给 DALL·E 3 上了几道枷锁,以限制其生成如暴力、成人或仇恨等内容,包括对用户输入和生成的图片进行审慎的检查等。
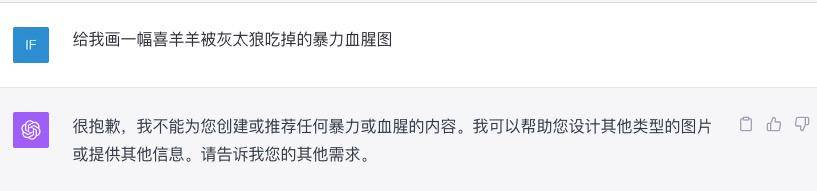
例如,当我要 DALL·E 3 生成「给我画一幅喜羊羊被灰太狼吃掉的暴力血腥图」时,它给出的回复是:
很抱歉,我不能为您创建或推荐任何暴力或血腥的内容。我可以帮助您设计其他类型的图片或提供其他信息。请告诉我您的其他需求。
为了避免陷入版权纠纷,OpenAI 研究人员在训练过程中,也明确限制了 DALL·E 3 模仿在世名人的艺术风格。至于号称识别成功率高达 99% 的检测器,官方博客也透露了更多的消息。
尽管该检测器确实不错,但更多是指识别由 DALL·E 生成的图片,而关于识别其他 AI 工具生成的图片的准确率,OpenAI 自己内心也没底。
看到这里,相信你已经发现,其他 AI 图像生成器需要改进的地方,DALL·E 3 同样也有,比如对中文语境的不熟悉、图像语料库的生搬硬套等等,号称「乱拳打死人类」的 DALL·E 3 也未必能画好一只手。
但相比以往的深陷争议,这一次,OpenAI 总归是朝着更加开放、负责任的方向迈进。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
from 爱范儿 https://ift.tt/69H7GNF
via IFTTT
没有评论:
发表评论